Тут мы обучим и развернем перцептрон, который умеет играть в игру «змейка» на микроконтроллере.
Давайте пофантазируем. Робот получил задание достать предметы из одной коробки и переложить их в другую. В течение ночи магический суперсекретный алгоритм будет сам пытаться понять, как выполнить поставленную задачу. К утру, пока инженеры спали, манипулятор уже освоит выполнение данной операции, как если бы он был запрограммирован толковым специалистом. Звучит интригующе, не так ли?
Один из возможных путей для решения таких задач это обучение с подкреплением. В чем его суть? Такой метод позволяет испытуемой системе (агенту) обучаться через взаимодействие с окружающей средой. Самое главное – робот сможет самостоятельно выяснить, как выполнять поставленные перед ним задачи. А специальные механизмы позволят технологическому решению каждый раз фиксировать успешность своих действий. Современные алгоритмы глубокого обучения с подкреплением способны решать задачи искусственного интеллекта методом проб и ошибок без использования каких-либо априорных знаний о решаемой задаче.
Бросаем бедного робота в реальную жизнь, будем штрафовать его за ошибки и награждать за правильные поступки. На людях работает, почему бы на и роботах не попробовать? Выживание в среде и есть идея обучения с подкреплением. Умные модели роботов-пылесосов и самоуправляемые автомобили обучаются именно так: им создают виртуальный город (часто на основе карт настоящих городов), населяют случайными пешеходами и отправляют учиться выживать. Когда робот начинает хорошо себя чувствовать в виртуальной среде, его выпускают тестировать на реальные улицы.
В качестве демки микроконтроллер сам игрет в игру змейка. С помощью алгоритма Q-learning змейка выбирает правильное действий из таблицы состояний. Что это за алгоритм такой и какие у него альтернативы расписано чуть ниже.
MSP430.js | ноутбук | исходники
Перед тем как погружаться в алгоритмы обучения с подкреплением, пожалуй стоит немного пробежаться по терминологии. Всего существует три основные категории машинного обучения. С одной мы уже сталкивались ранее, когда обучали перцептрон выполнять операцию XOR:
-
Supervised learning (обучение с учителем): Машина учится по обучающей выборке, в которой есть входные и выходные данные. Это наиболее распространенный и изученный тип машинного обучения. Например задачи регрессии / классификации котиков и собачек входят в данную категорию
-
Unsupervised learning (обучение без учителя): Есть набор входных данных, но нет выходных, т.е. среди данных нет «правильного» ответа, машина должна сама найти зависимость между объектами в процессе обучения. Например задача кластеризации или автоэнкодеры для подавления шумов / сжатия данных с потерями
-
Reinforcement learning (обучение с подкреплением): Машина учится, не имея полных сведений о системе, но имея возможность наблюдать какие-то признаки и производить какие-либо действия в ней. Действия переводят систему в новое состояние и модель получает от системы некоторое вознаграждение / штраф. Обучение с подкреплением используют там, где задачей стоит не анализ данных, а выживание в реальной среде и получение максимального вознаграждения (кумулятивная награда – сумма наград за каждое принятое решение)
-
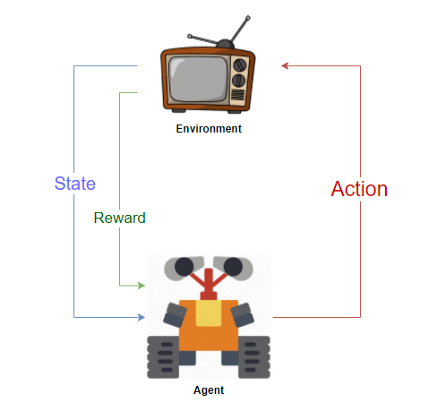
Агентом мы будем называть наш алгоритм, который умеет анализировать состояние среды и совершать в ней какие-то действия
-
Среда – мир в котором существует наш Агент и своими действиями может менять состояние
-
Награда – обратная связь от Среды к Агенту как ответ на его действия
В каждый момент времени t наш агент наблюдает состояние среды – S(t), выполняет действие – a(t), за что получает от среды награду – r(t), поле чего среда переходит в состояние S(t+1). Затем агент опять выполняет действие – a(t+1), за что получает от среды награду – r(t+1) и таких состояний t у нас может быть множество n до тех пор пока эпизод (игра) не закончится. Также для простоты далее будем считать синонимами состояние и наблюдение, хотя формально это разные вещи так как агент может наблюдать не все отстояние среды а только ее часть.
В нашем случае с игрой «змейка» награда +1 если змейка скушала яблоко, -1 если игра окончена. В остальных случаях награда 0.
REINFORCE
Начнем с самого простого алгоритма обучения с подкреплением – Reinforce, который принадлежит к семейству Policy Gradient (градиент политики). Здесь будут использоваться нейросети, поэтому для понимания данного алгоритма нужно уже иметь представление что это и как их обучать.
Алгоритм Reinforce был предложен Рональдом Дж. Вильямсом в 1992 году. Способен обрабатывать как непрерывное пространство с бесконечным количеством состояний, так и дискретное. Алгоритм строит параметризированную стратегию, которая получает вероятности действий по состояниям среды. Агенты непосредственно используют эту стратегию, чтобы действовать в среде. Основной смысл заключается в том, что во время обучения действия, которые приводят к хорошим результатам, должны иметь большую вероятность – они положительно подкрепляются. В противовес этому действия, приводящие к плохим результатам, должны иметь меньшую вероятность. Если обучение успешно, то за несколько итераций распределение полученных стратегией вероятностей действий станет таким, которое приводит к повышению производительности в среде.
Оптимальна та стратегия, которая максимизирует суммарное вознаграждение. Основной смысл алгоритма – настроить хорошую стратегию, а это подразумевает аппроксимацию функции. Нейронные сети – эффективный и гибкий метод аппроксимации функций, так что стратегия может быть представлена как глубокая нейронная сеть.
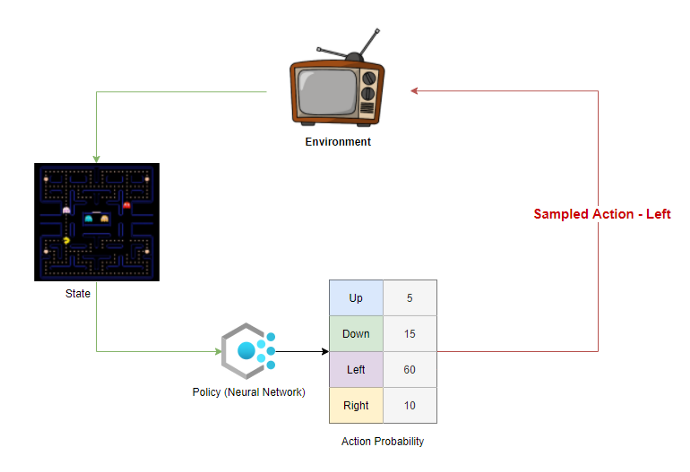
На вход нейронной сети будем подавать наблюдения S(t), а выход нейросети сконструируем таким образом, чтобы в выходным слое количество выходов было равным количеству действий возможных для агента в нашей среде. Таким образом пропустив через слои нейросети наблюдение S(t) на выходе мы получим некое распределение для действий агента – Policy Function. Она показывает нам насколько действие a(t) при состоянии / наблюдении S(t) оптимально. Если прогнать последний слой нейросети через активация Softmax активацию, то получится вероятностное распределение p(a|s) – функция вероятности оптимальности действия a(t) в зависимости от состояния среды.
Алгоритм Reinforce в сочетании с нейронными сетями позволяет оптимизировать Policy Function через алгоритм обратного распространения ошибки, обучая нашу нейросеть итеративно. Все очень похоже на обычное обучение с учителем. Нужен набор данных, нейросеть, функция потерь (Loss) и метод градиентного спуска для обучения.
Loss
Как обучают нейросети отличать кошечек от собачек? Последний слой нейросети имеет вероятностное распределение SoftMax, для обучения сети применяют Categorical Cross Entropy Loss:
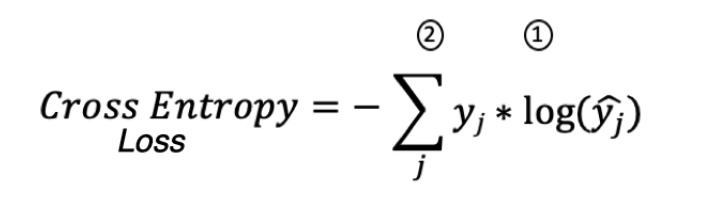
На картинке: y слева истинные метки, y справа предсказанные метки
Однако в случае обучения с подкреплением у нас нет истинных меток для действий агента в состояниях S(0..n), как же нам обучать нейросеть в этом случае? Можем ли мы вместо правильных (истинных) меток использовать награду, которую агент получил от среды выполнив действие которое ему предсказала нейросеть? Функцию потерь, адаптированную под обучение с подкреплением, можно представить так:
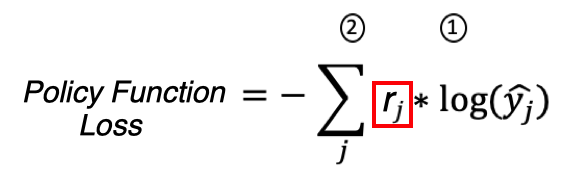
Имеем право так сделать потому, что yj для Categorical Cross Entropy Loss – это истинные метки вероятности и для правильного класса они равны единице, а rj для Policy Function Loss – награда которую среда начислила агенту за действие которое он совершил. То есть rj служит как бы весом для градиентов при обратном распространении ошибки когда мы обучаем нейросеть. Награды становятся обучающими данными. Если получена положительная награда, имеет смысл считать все предпринятые действия более-менее правильными – а значит, можно посчитать градиенты точно таким же методом, каким мы считали бы их в обучении с учителем. То же самое верно в случае, если получена отрицательная награда – только вместо увеличения вероятности совершенных действий в будущем, ее следует уменьшать. Градиентный спуск и обновление градиентов происходит таким образом, чтобы действия, обеспечивающие высокую награду в состоянии, имели высокую вероятность, а действия с низкой наградой – низкую.
Rollout
Создаем змейку env = SnakeGame(), прогоняем эпизоды, собирем датасет. Прогон одного эпизода в обучении с подкреплением часто называют Rollout. Датасет состоит из наблюдений, действий и полученных наград.
def play_game():
env.reset()
game_data = []
done = False
while not done:
features = extract_features()
action = model(tf.expand_dims(features, 0), training=False)
action = tf.squeeze(tf.random.categorical(action, 1))
_, reward, done, info = env.step(action)
game_data.append((features, action, -1e-2 if reward < 0 else reward))
return game_data, info.score
Для простоты и скорости обучения наблюдение features состоит только из координат головы змейки и координат еды, т.е. геометрию тела змейки пока не учитываем. Также в наблюдение попадает информация о препятствиях по отношении к голове змейки – есть ли препятствие слева, справа, сверху или снизу.
def extract_features(game=env):
obsticle = lambda k: copy.deepcopy(game).step(k).done
snake, food = game.get_state()
head, food = [h + w * game.board_height for h, w in (snake.head, food)]
obs = sum(v << i for i, v in enumerate(obsticle(k) for k in game.ACTION))
max = game.board_height * game.board_width - 1
return obs / 0b1111, head / max, food / max
Такие же ограничения накладываются и на признаки Q-learning, которое будет описано ниже. Это позволит равноценно сравнивать качество обоих алгоритмов Reinforce и Q-learning на примере змейки.
Exploration vs Exploitation
Очевидно что пространство возможных состояний среды надо исследовать (разведать), чтобы иметь понятие о том, какой вариант реакции на текущее состояние самый лучший. Если мы сначала обнаружили этот самый оптимальный вариант, а потом все время его используем – мы максимизируем суммарную награду, которая нам доступна из окружающей среды? С другой стороны, мы также хотим исследовать другие возможные варианты – вдруг они в будущем окажутся лучше, а мы просто этого пока не знаем? В процессе обучения нужен компромисс между исследованием и эксплуатацией (Exploration vs Exploitation).
На начальном этапе нейросеть ничего не знает о среде, она даёт на выходе случайные, хоть и детерминированные действия. В нашем случае она на любые данные будет выдавать примерно одинаковую вероятность для всех возможных действий змейки, т.е. мы будем максимально исследовать среду. По мере обучения вероятность одного действия будет преобладать над другими. Если вероятность одного действия достигнет 1, значит нейросеть абсолютно уверена в своем действии и для данного состояния исследовать уже нечего. За баланс исследования и эксплуатации в процессе обучения нейросети отвечает функция tf.random.categorical.
Discount
Положительная или отрицательная награда у агента может случается крайне редко, в основном же награда вне зависимости от его действий равна нулю. Как же обучать Агента кода основное время он не получает отклика от среды на свои действия? Ведь если награда от среды равна нулю, то и градиенты при обратном распространении ошибки через нейросеть в этом случае равна нулю, весам нейросети меняться будет некуда, значит и наш агент ничему не будет учиться. Как же решить проблему с нулевой наградой в большей части датасета который собирается для обучения агента?
Обычно вводится дисконтированная награда за действие с убыванием по мере удаления действия от финала эпизода. Тем самым мы даем Агенту понять, что последние действия которые он предпринимал, более важны для результат эпизода игры, чем те действия которые он предпринимал вначале.
Train
Создадим простую нейронную сеть – классический многослойный перцептрон вполне подойдет. Обучать будем на Keras / Tensorflow:
x_in = x = keras.Input(shape=(3,))
x = keras.layers.Dense(32, activation='relu')(x)
x = keras.layers.Dense(32, activation='relu')(x)
x = keras.layers.Dense(len(env.ACTION))(x)
model = keras.Model(x_in, x)
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='Nadam')
Единственное отличие от привычного нам обучения с учителем это параметр sample_weight, в который передаются дисконтированные награды.
history = []
while len(history) < episodes_to_play:
data, score = play_game()
X, Y, R = [tf.stack(i) for i in zip(*data)]
history.append((model.train_on_batch(X, Y, sample_weight=disc(R)), score))
Дисконтированные награды высчитываются по окончании эпизода и только после этого можно обновлять веса нейростети. Это один из недостатков алгоритма Reinforce так как эпизод может быть очень растянутым во времени, а время как известно стоит денег.
disc = lambda r: tf.scan(lambda a, x: x + .9 * a, r, reverse=True)
Змейка определенно обладает признаками интеллекта, но явно им не блещет. Она не всегда выбирает наиболее короткий путь, иногда перестает кушать. В общем много денег на такой змейке мы не заработаем, но для погружения в обучение с подкреплением метод Reinforce точно годится, тем более что есть различные модификации данного алгоритма и сочетания с другими.
Q-LEARNING
Алгоритм Reinforce относится к policy-based методам обучения с подкреплением. Есть и другой подход к решению задачи, value-based, в котором алгоритм ищет не саму стратегию, а некоторую оптимальную функцию полезности действия Q-function. Говоря математическим языком, существует некая функция Q, которая в зависимости от состояния s и действия a возвращает кумулятивное вознаграждение R и обозначается Q(s|a). Здесь надо обратить внимание, что Q-функция не предсказывает полученное вознаграждение, т.е. R != r(t). Она лишь возвращает ожидаемое (кумулятивное) вознаграждение на основании прошлого опыта взаимодействия агента со средой в случае, если мы будем действовать оптимальным образом. Изначально агенту неизвестна эта функция, но если она существует, то в процессе взаимодействия со средой, повторяя действия достаточное количество раз, мы можем её аппроксимировать с приемлемой погрешностью.

Цель обучения нашего агента – максимизация совокупной награды. На рисунке ниже агенту предстоит перейти из клетки Start в клетку Finish. Награду агент получает одноразово при попадании в клетку Finish. Во всех остальных состояниях награда нулевая.
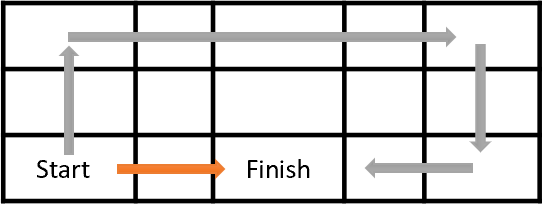
Очевидно, что оранжевый путь короче и более предпочтителен. Но с точки зрения максимизация награды они равнозначны. Для решения проблемы вводится фактор дисконтирования ɣ, который будет уменьшать ценность будущих наград.
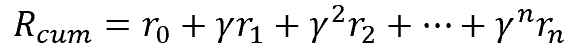
Фактор дисконтирования ɣ выбирается в диапазоне от 0 до 1. В таком случае в состоянии Start кумулятивная награда для действия вверх будет меньше чем для действия вправо. Мы предпринимаем действия, которые имеют наибольшую ценность в каждом состоянии. Когда мы делаем это, мы используем наши Q-values для создания политики. Это будет жадная политика, потому что мы всегда предпринимаем действия, которые, по нашему мнению, лучше всего в каждом состоянии, поэтому говорится, что мы действуем жадно. Выбирая на каждом шаге действие с максимальным вознаграждением мы получим максимальную кумулятивную награду.
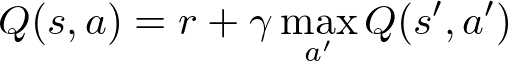
Данное уравнение, которое называют уравнением Беллмана, утверждает что значение Q для определенной пары состояние-действие должно быть наградой r, полученной при переходе в новое состояние (путем выполнения этого действия), добавленной к значению Q наилучшего действия в следующем состоянии с каким-то дисконтом.
Суть Q-learning сводится к тому, то мы можем итеративно аппроксимировать Q-функцию используя уравнение Беллмана. Другими словами, мы распространяем информацию о значениях действий по одному шагу за раз.
Теперь, когда у нас есть интуитивное представление о том, как работает Q-learning, мы можем начать думать о реализации всего этого. Мы создадим таблицу для всех возможных состояний и действий для змейки env = SnakeGame(). Проинициализировать таблицу можно любыми значениями, которые нам нравятся – они могут быть случайными, они могут быть какими-то постоянными. Мы создадим таблицу, заполненную случайными действиями, т.е. изначально всех четырех действий там примерно поровну, что в свою очередь позволит избежать проблемы дисбаланса классов в случае, если нам потребуется сжать таблицу с помощью нейросети.
action_space_size = len(env.ACTION)
qtable = np.random.rand(
1 << action_space_size,
env.board_height, env.board_width,
env.board_height, env.board_width,
action_space_size)
Состояние змейки в какой-либо момент берется упрощенное – координаты головы, яблока, наличие препятствий слева, справа, сверху, снизу. Состояние тела не учитывается.
def extract_features(game=env):
snake, food = game.get_state()
obsticle = lambda k: copy.deepcopy(game).step(k).done
obs = sum(v << i for i, v in enumerate(obsticle(k) for k in game.ACTION))
return obs, snake.head.h, snake.head.w, food.h, food.w
Если бы мы захотели учитывать координаты частей тела змейки, тогда, размер таблицы резко возрастет. Даже если исходить из относительных координат частей тела относительно предыдущих, то координаты каждой из них умножают размер таблицы на 5 (отсутствует, слева, справа, сверху, снизу). Частей тела может быть 32 * 16 - 2 = 510. Получаем 5**510 это очень большое число галактических масштабов, ни один компьютер в мире не обладает таким размером памяти.
Важной особенностью Q-learning является то, что обучение происходит не дожидаясь окончания эпизода в отличие от Reinforce алгоритма. Гиперпараметры ALPHA, GAMMA и epsilon влияют на скорость и качество обучения. Так же как и в случае с Reinforce нужен компромисс между разведкой и эксплуатацией. За это отвечает переменная epsilon. На начальном этапе большинство действий агента являются случайными. В процессе обучения баланс меняется в обратную сторну.
# Until learning is stopped
while len(history) < total_episodes:
# Reset the environment
env.reset()
state = extract_features()
done = False
# Reduce epsilon (because we need less and less exploration)
epsilon = (max_epsilon - min_epsilon) * np.exp(-epsilon_decay * len(history))
epsilon += min_epsilon
while not done:
# Choose an action a in the current world state (s)
# First we randomize a number
exp_exp_tradeoff = np.random.random()
# If this number > greater than epsilon -->
# exploitation (taking the biggest Q value for this state)
if exp_exp_tradeoff > epsilon:
action = np.argmax(qtable[state])
# Else doing a random choice --> exploration
else:
action = env.random_action()
# Take the action (a) and observe the outcome state(s') and reward (r)
_, reward, done, info = env.step(action)
new_state = extract_features()
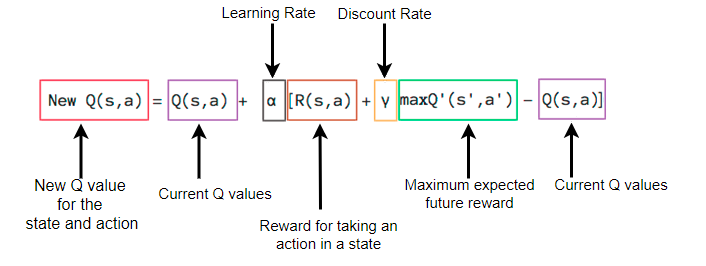
# Update Q(s,a):= Q(s,a) + lr * [R(s,a) + GAMMA * max Q(s',a') - Q(s,a)]
i = state + (action,)
qtable[i] += ALPHA * (reward + GAMMA * qtable[new_state].max() - qtable[i])
# Our new state is state
state = new_state
history.append(info.score)
Алгоритм Q-learning часто используют в сочетании с нейронными сетями. В самом простейшем случае таблицу Q-table можно сначала обучить, а затем сжать используя ее данные как готовый датасет для обучения с учителем. Однако часто среда имеет слишком много состояний и действий, поэтому составить таблицу в явном виде невозможно. Для решения этой проблемы также используют нейронные сети, чтобы не хранить значения полезности, а предсказывать их. На вход нейросети поступает текущее состояние среды, а на выход она дает прогнозируемую награду для всех действий. Для изменения Q-value мы обновляем параметры нейронной сети, чтобы предсказывать более точные значения. Такие нейронные сети называют DQN (Deep Q Networks).
DEEP Q-NETWORK (DQN)
Заменив таблицу значений Q-table на нейронную сеть, мы получаем DQN. В DQN на вход нейросети подается текущее состояние, а на выходе нейросеть предсказывает ценность Q-value всех возможных действий для этого состояния.
В процессе обучения модели агент действует в окружающей среде и хранит все переходы, выполняемые им, в буфере примеров replay buffer. Для вычисления ошибки мы равномерно выбираем данные из буфера – так же, как мы бы делали это в ходе обычного обучения с учителем и сравниваем значения текущих выходных Q-value из нейросети с целевыми рассчитанными по уравнению Беллмана.
На вход нейросети поступает все состояние змейки с учетом геометрии тела. Действия на выходе DQN змейки более оптимальны чем при алгоритме Reinforce – последний заучивает только два действия из четырех возможных т.е. впадает в локальный минимум.
Обучение DQN это длительный процесс, поэтому лучше это делать в облаке. В нашем случае змейка живет и учится в kaggle, там же всегда можно скачать более актуальную модель на текущий момент.