В будущем радио будет преобразовано в «большой мозг», все вещи станут частью единого целого, а инструменты, благодаря которым это станет возможным, будут легко помещаться в кармане. — Никола Тесла
Тренд «интернета вещей» (Internet of Things, IoT) сейчас набирает всё большую популярность. Лень — двигатель прогресса, и исходя из этого появление «интернета вещей» вполне логичный этап эволюции Homo sapiens. Зачем подходить к телевизору для переключения каналов, если можно придумать дистанционный пульт управления, зачем нажимать кнопочку на кофеварке, если можно сделать это в смартфоне или настроить правило, чтобы кофе наливался сам… Звучит заманчиво, но как это работает ? Как организовать надёжный и безопасный обмен данными ?
Современная концепция «интернета вещей» подразумевает, что все современные устройства независимо от платформы должны иметь возможность взаимодействовать с другими устройствами и сервисами, образуя единую взаимосвязанную экосистему — сеть. Тут нет смысла изобретать заново велосипед, поскольку исторически Internet Protocol (IP, «межсетевой протокол») уже является тем протоколом, который объединил отдельные компьютерные сети во всемирную сеть Интернет. С учётом потенциально очень большого и постоянно растущего количества различных «интернет вещей» для создания сетей IoT как нельзя лучше подходит IPv6, ведь адресное пространство тут практически неисчерпаемое.
TL;DR
Часики берут данные времени из интернета по NTP (Network Time Protocol — протокол сетевого времени). Под капотом часов используется Contiki — компактная, свободная, переносимая, многозадачная операционная система для встраиваемых систем. Процессы Contiki используют облегчённую потоковую модель — протопотоки, в основе которых лежит кооперативная многозадачность. Где-то сбоку к Contiki можно прикрутить ещё и вытесняющую многозадачность через некую библиотеку
mt library, но нам это не понадобится. Всё же главная ценность Contiki это конечно же встроенный TCP/IP стек uIP (micro IP), который оптимизирован с точки зрения ресурсов памяти и в частности не использует динамически выделяемую память (кучу).
~$ getm(){ echo $((0x`printf c%47s|nc -uw1 "$@"|xxd -s40 -l4 -p`-64#23GDW0)); }
~$ date -d @`getm pool.ntp.org 123`
~$ printf '%(%m-%d-%Y %H:%M:%S)T\n' `getm pool.ntp.org 123`
NTP работает поверх UDP (User Datagram Protocol — протокол пользовательских датаграмм). В исходниках можно встретить и другие умные слова — например DNS (Domain Name System — система доменных имён). Пример интересен тем, что все протоколы в данных часиках используют только UDP. Кто такой UDP и зачем он нужен будет подробно расписано ниже, а для симуляции данных примеров можно использовать mspsim.js.jar ну и неплохо бы почитать инструкцию.
IPv6 | IPv4 | исходники
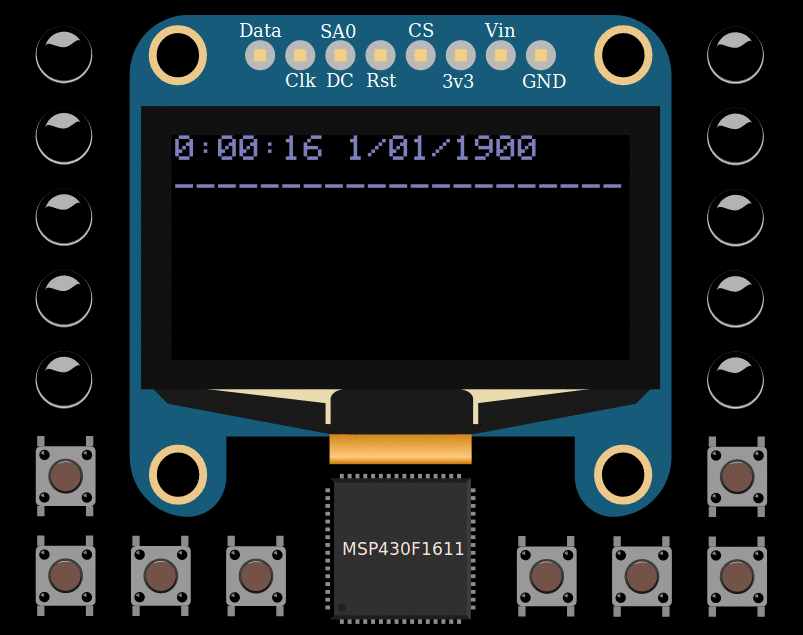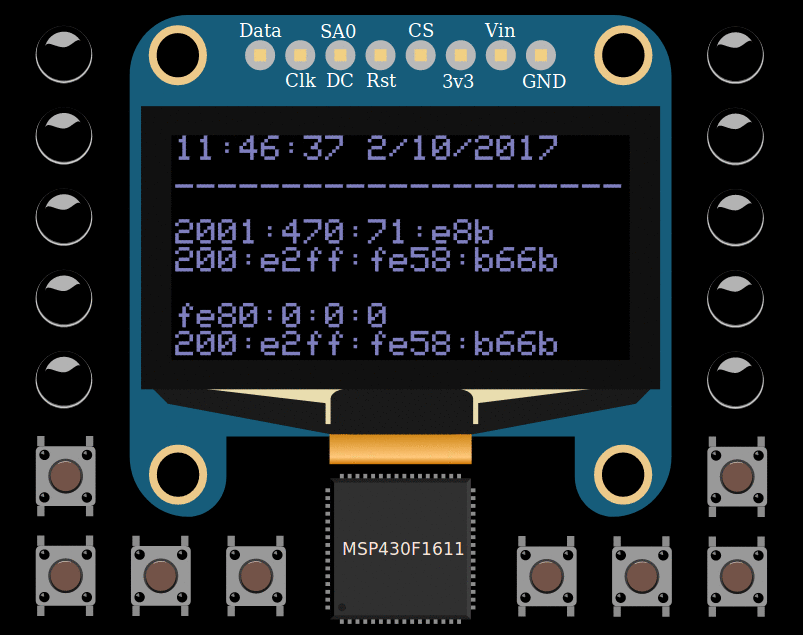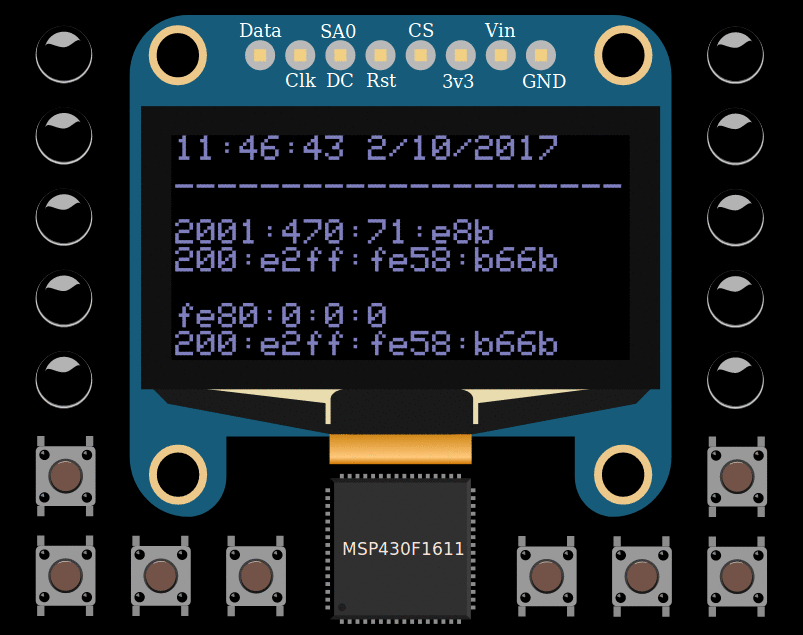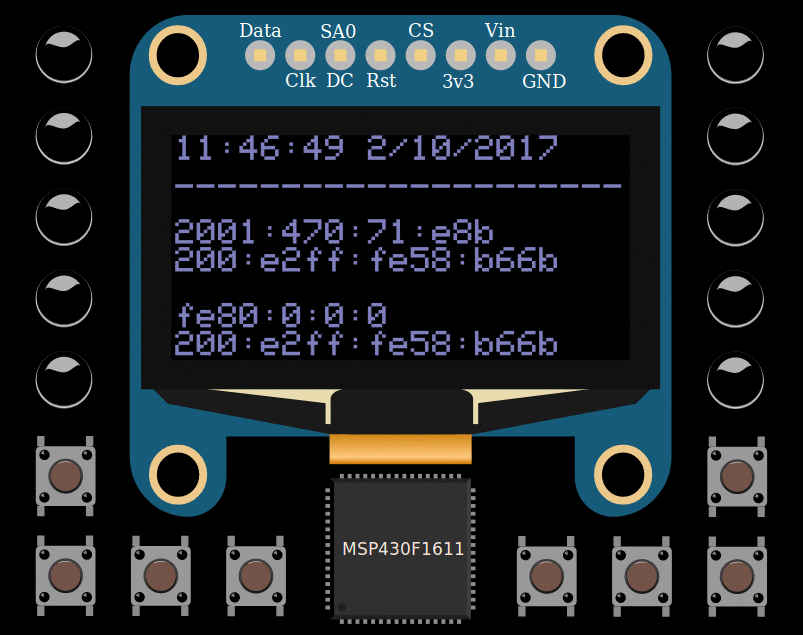
Адрес протокола IPv6 состоит из 128 бит и записывается обычно в шестнадцатеричном виде. Адрес разбиваются на блоки по 16 бит (хекстеты) и каждый блок представляется четырьмя шестнадцатеричными цифрами. Хекстеты разделяются знаком двоеточия. Таким образом, адрес получается достаточно длинным – он состоит из 32 шестнадцатеричных цифр и 7 знаков двоеточия.
При инициализации сетевого интерфейса ему автоматически назначается локальный IPv6-адрес, состоящий из префикса fe80::/10 и идентификатора интерфейса, размещённого в младшей части адреса. В качестве идентификатора интерфейса часто используется модифицированный MAC-адрес самого устройства. Локальный адрес позволяет обмениваться данными с другими устройствами под управлением IPv6 только в пределах своей подсети. IPv6 адреса можно записывать, а иногда даже и запоминать, в сокращенном виде – например если две и более групп подряд равны 0000, то они могут быть опущены и заменены на двойное двоеточие (::), т.е. fe80:0:0:0:200:e2ff:fe58:b66b может быть сокращён до fe80::200:e2ff:fe58:b66b.
Для выхода за пределы своей подсети, например запросить данные через интернет, устройству нужно получить глобальный индивидуальный адрес. В данном случае этот адрес раздаётся демоном radvd ну и дальше RTFM.
ENC28J60
ENC28J60 — Ethernet-адаптер (проще говоря, «сетевая карточка») на одном чипе от компании Microchip. Микросхема очень дешевая, не требует для работы много обвязки из внешних компонентов, к микроконтроллеру (в нашем случае это MSP430F1611) подключается с помощью SPI. Полностью соответствует спецификации Ethernet IEEE 802.3. В ENC28J60 есть буфер размером 8 КБ – часть этого буфера обычно выделяется для приёма пакетов, остальное можно использовать как угодно, например для отправляемых данных. Управляющие регистры делятся на 4 банка (Microchip любит банки). Каждый банк имеет размер в 32 регистра, причём последние 5 ячеек (0x1b..0x1f) всегда мапятся на одни и те же регистры, вне зависимости от того, какой банк выбран.
Обмен данными с ENC28J60 по SPI выполняется транзакциями. Начало транзакции – нога CS в ноль, затем отправки команды, затем идут опциональные данные (приём или передача). Завершается транзакция «поднятием» ножки CS. После инициализации микросхемы работа с ней сводится к двум функциям – отправка / приём пакетов. Эти пакеты обрабатывает TCP/IP стек в микроконтроллере.
UDP
Здесь мы набросаем простейший TCP/IP стек для обмена данными по UDP. Страшно ? На рисунке ниже отображена т.н. TCP/IP сетевая модель и как через неё проходят UDP пакеты. Данная модель разбивает коммуникационную систему на простые части, называемые уровнями или слоями. Уровни протоколов TCP/IP расположены по принципу стека — это означает, что протокол, располагающийся на уровне выше, работает «поверх» нижнего, используя механизмы инкапсуляции. Например, протокол UDP работает поверх протокола IP. Ethernet пакеты ENC28J60 попадают на канальный уровень. При прохождении пакета вниз по стеку, к нему прикрепляются заголовки протоколов.

В теории уровни сетевой модели должны быть изолированы друг от друга. Но у нас будет не совсем так, все протоколы будут работать с одним и тем же пакетом, но обращаться к своим заголовкам. Это позволит сэкономить память и такты микроконтроллера. Для такого простого стека это вполне нормально.
Порядок байтов в TCP/IP от старшего к младшему (big-endian — большим концом), для перекодирования в нормальный формат и обратно используют htons/ntohs и htonl/ntohl:
-
htonl (host to network long) преобразует 32-битное целое из порядка байт хоста в сетевой порядок байт
-
ntohl (network to host long) преобразует 32-битное целое из сетевого порядка байт в порядок байт хоста
-
htons / ntohs то же самое, только для 16-бит
При проектировании стандарта Ethernet было предусмотрено, что каждая сетевая карта должна иметь уникальный шестибайтный номер (MAC-адрес), «прошитый» в ней при изготовлении. Этот номер используется для идентификации отправителя и получателя фрейма. Уникальность MAC-адресов достигается тем, что каждый производитель получает его в какой-то там специальной конторе IEEE. На практике обычно за это отвечает совсем копеечная микросхема ПЗУ, которую микроконтроллер считывает при старте. В нашем экспериментальном TCP/IP стеке мы сами придумаем MAC-адрес и он будет в прошивке самого микроконтроллера. Локальный адрес IPv6 формируется на основе мак адреса по определённому алгоритму:
static const uint8_t mac_addr[6] = { 2, 0, 0, 0, 0, 0x42 };
// https://stackoverflow.com/a/37316533
// 02:00:00:00:00:42 => fe80::0:0ff:fe00:42
static const union {
uint8_t u6_addr8 [16];
uint16_t u6_addr16 [8];
uint32_t u6_addr32 [4];
} my_ip = { .u6_addr16 = { htons(0xfe80), 0, 0, 0, 0,
htons(0xff), htons(0xfe00), htons(0x42) }
};
MAC делится на две части: OUI (который однозначно указывает на производителя) и NIC Specific (выбираются изготовителем для каждого экземпляра устройства). При этом в самом первом октете используются только шесть старших разрядов, а два младших имеют специальное назначение. Если восьмой бит выставлен в 1 (например 01:00:00:00:00:00), то адрес multicast, иначе unicast. Если седьмой бит равен единице (например 02:00:00:00:00:00), то адрес является т.н. locally administered адресом, т.е. назначен вручную или же его использует железо/софт, которым IEEE не выделила OUI. Если захочется придумывать свой MAC-адрес, проще всего просто обнулить первый октет.
И собственно вот так выглядит Ethernet-фрейм на канальном уровене:

Контрольная сумма рассчитывается и проверяется ENC28J60, так что для нас остаются видимы только 4 поля:
-
MAC-адрес получателя
-
MAC-адрес отправителя
-
здесь находится идентификатор протокола, например 0x86DD для IPv6
-
поле данных — полезная нагрузка, например IP-пакет, обычно от 60 до 1500 байт
Пакеты, считываемые с ENC28J60, обрабатываются функцией eth_filter. При отправке ответа на Ethernet-фрейм обычно достаточно обменять местами MAC-адрес отправителя и получателя. В коде это выглядит следующим образом:
typedef struct eth_frame {
uint8_t to_addr[6];
uint8_t from_addr[6];
uint16_t type;
uint8_t data[];
} eth_frame_t;
#define ETH_TYPE_IP6 htons(0x86DD)
static void eth_reply(eth_frame_t *frame, uint16_t len)
{
memcpy(frame->to_addr, frame->from_addr, sizeof mac_addr);
memcpy(frame->from_addr, mac_addr, sizeof mac_addr);
enc28j60_send((void*)frame, len + sizeof(eth_frame_t));
}
static void eth_filter(eth_frame_t *frame, uint16_t len)
{
if(len >= sizeof(eth_frame_t))
{
switch(frame->type)
{
case ETH_TYPE_IP6:
ip_filter(frame, len - sizeof(eth_frame_t));
break;
}
}
}
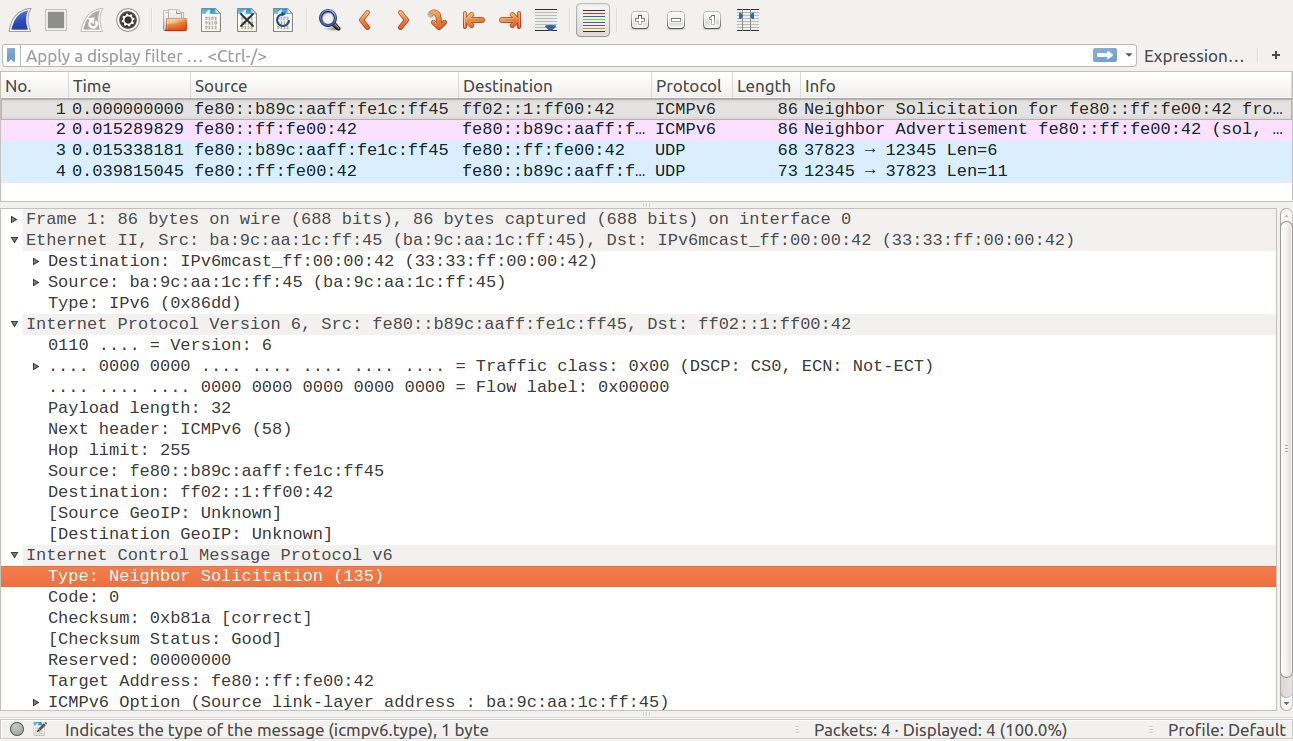
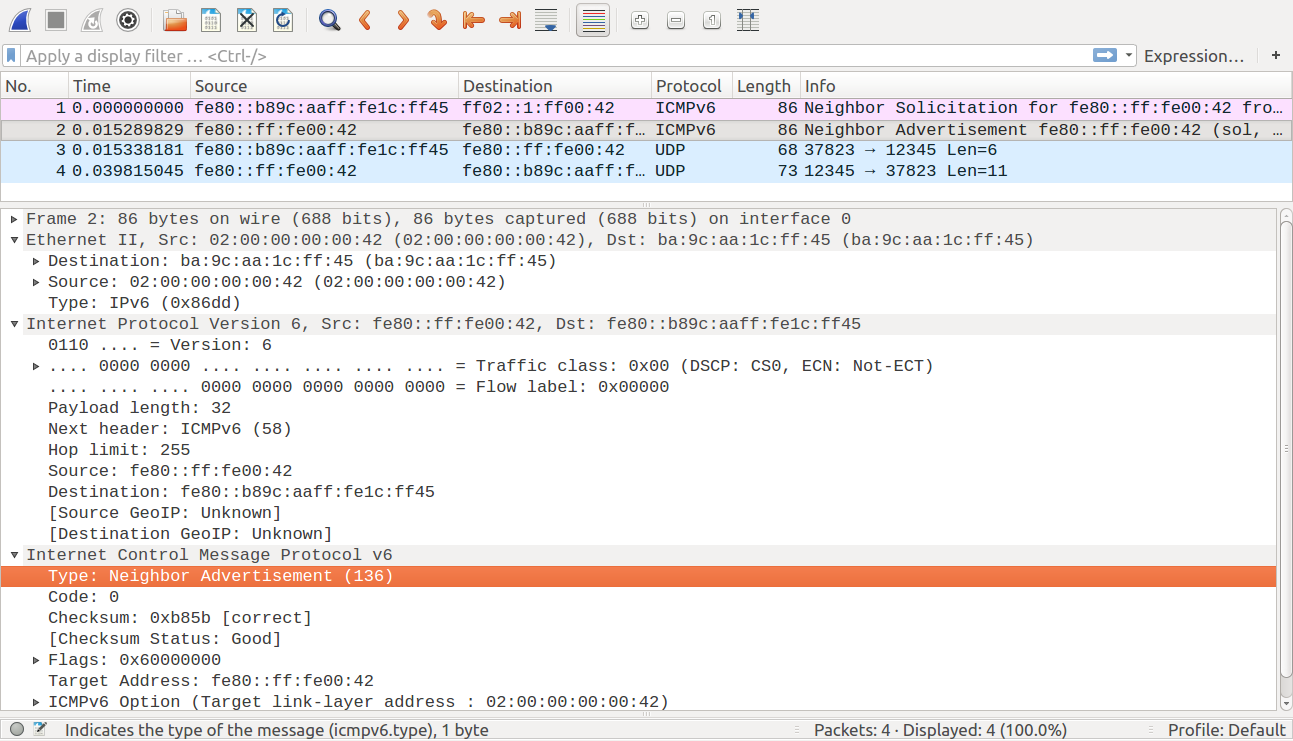
Сразу после включения устройство знает только свой MAC-адрес, как оно узнает MAC-адрес получателя ? В IPv6 для этого предусмотрен протокол обнаружения соседей (Neighbor Discovery Protocol, NDP). Он работает на сетевом уровне TCP/IP. Вот как это выглядит в Wireshark:
# sudo ip neigh flush to fe80::0:ff:fe00:42
~$ echo hello | nc -6 -u fe80::0:ff:fe00:42%mazko 12345
При отправке первых данных неизвестно, у какого устройства в подсети адрес fe80::0:ff:fe00:42. Узел, который хочет узнать MAC-адрес другого узла, посылает специальный ICMPv6-запрос Neighbor Solicitation (135) с IP-адресом искомого узла на специальный мультикаст-адрес. Узел, чей IP указан в пакете, отвечает обратно ICMPv6-пакетом — Neighbor Advertisement (136), в котором и указывает свой MAC-адрес.
Пример кода:
typedef struct ip_packet {
/** Version (4 bits), Traffic class (8 bits), Flow label (20 bits) */
uint32_t ver_tc_label;
/** Payload length, including any extension headers */
uint16_t payload_len;
/** Next header type */
uint8_t next_header;
/** Hop limit */
uint8_t hop_limit;
/** Source address, Destination address */
union {
uint8_t u6_addr8 [16];
uint16_t u6_addr16 [8];
uint32_t u6_addr32 [4];
} src, dest;
uint8_t data[];
} ip_packet_t;
typedef struct icmp_packet {
uint8_t type;
uint8_t code;
uint16_t cksum;
uint32_t flags;
uint8_t data[];
} icmp_packet_t;
static void icmp_filter(eth_frame_t *frame, uint16_t len)
{
ip_packet_t *packet = (void*)frame->data;
icmp_packet_t *icmp = (void*)packet->data;
struct {
uint8_t target_address_u6_addr8[sizeof my_ip];
uint8_t type;
uint8_t length;
uint8_t addr[sizeof mac_addr];
} *option = (void*)icmp->data;
if( len >= sizeof(icmp_packet_t) + sizeof *option )
{
if(icmp->type == ICMP_TYPE_NEIGHBOR_SOLICITATION && icmp->code == 0)
{
icmp->type = ICMP_TYPE_NEIGHBOR_ADVERTISEMENT;
icmp->flags = htonl(0x60000000); // Solicited: Set, Override: Set
icmp->cksum = 0;
option->type = 2; // Type: Target link-layer address (2)
memcpy(option->addr, mac_addr, sizeof mac_addr);
memcpy(&packet->dest, &packet->src, sizeof packet->src);
memcpy(&packet->src, &my_ip, sizeof packet->src);
icmp->cksum = ip_cksum(len + IP_PROTOCOL_ICMP6,
(void *)&packet->src, len + (2 * sizeof my_ip));
eth_reply(frame, len + sizeof(ip_packet_t));
}
}
}
static char toMe(uint32_t u6_addr32[4]) {
return
( !memcmp(&my_ip, u6_addr32, sizeof my_ip) ) ||
// multicast
( u6_addr32[0] == htonl(0xff020000) &&
u6_addr32[1] == 0 && u6_addr32[2] == htonl(1l) &&
u6_addr32[3] == (my_ip.u6_addr32[3] | htonl(0xff000000)) );
}
static void ip_filter(eth_frame_t *frame, uint16_t len)
{
ip_packet_t *packet = (void*)(frame->data);
if(len >= sizeof(ip_packet_t))
{
if( (packet->ver_tc_label & IPV6_MASK_VER) == IPV6_VER
&& toMe(packet->dest.u6_addr32) ) {
const uint16_t p_len = ntohs(packet->payload_len);
switch(packet->next_header)
{
case IP_PROTOCOL_ICMP6:
icmp_filter(frame, p_len);
break;
case IP_PROTOCOL_UDP:
udp_filter(frame, p_len);
break;
}
}
}
}
Осталось совсем чуть чуть. UDP (User Datagram Protocol) — простейший протокол транспортного уровня. UDP позволяет узлам обмениваться небольшими сообщениями, называемыми датаграммами. Мы реализуем UDP-сервер на микроконтроллере. Для простоты опускаем тему фрагментации IP-пакета, это допустимо для небольших данных. Например для IPv4 чтобы датаграмма точно пролезла без фрагментации IP-пакета, количество полезных данных в ней не должно превышать 512 байт, для IPv6 нужно пересчитать, но что-то близкое к этому.
UDP считается ненадёжным протоколом — при потере IP-пакета, датаграмма теряется. Впрочем, современные сети вполне себе надёжны — в хорошо работающей локальной сети пакеты не теряются почти никогда. Но, естественно, приложение должно адекватно реагировать, если датаграмма всё же потеряется. Порядок доставки датаграмма также не гарантируется — теоретически вы можно отправить два пакета hello затем world, а получить world затем hello.
UDP отлично подходит для передачи данных в реальном времени, нечувствительных к потерям. Скажем, с помощью UDP удобно забирать показания каких-нибудь датчиков или отправлять информацию на дисплей или даже голосовой или видео поток в реальном времени.
typedef struct udp_packet {
uint16_t from_port;
uint16_t to_port;
uint16_t len;
uint16_t cksum;
uint8_t data[];
} udp_packet_t;
void udp_reply(eth_frame_t *frame, uint16_t len)
{
ip_packet_t *ip = (void*)(frame->data);
udp_packet_t *udp = (void*)(ip->data);
uint16_t temp;
len += sizeof(udp_packet_t);
temp = udp->from_port;
udp->from_port = udp->to_port;
udp->to_port = temp;
udp->len = htons(len);
ip->payload_len = udp->len;
udp->cksum = 0;
udp->cksum = ip_cksum(len + IP_PROTOCOL_UDP,
(void *)&ip->src, len + (2 * sizeof my_ip));
memcpy(&ip->dest, &ip->src, sizeof ip->src);
memcpy(&ip->src, &my_ip, sizeof ip->src);
eth_reply(frame, len + sizeof(ip_packet_t));
}
static void udp_filter(eth_frame_t *frame, uint16_t len)
{
const ip_packet_t *ip = (void*)(frame->data);
const udp_packet_t *udp = (void*)(ip->data);
if(len >= sizeof(udp_packet_t))
{
const uint16_t udp_len = ntohs(udp->len) - sizeof(udp_packet_t);
udp_packet(frame, udp_len);
}
}
Чтобы придать всему этому смысл, напишем простенькое приложение, работающее по UDP. Например, печатаем текст на дисплее устройства с микроконтроллером.
void udp_packet(eth_frame_t *frame, uint16_t len)
{
ip_packet_t *ip = (void*)(frame->data);
udp_packet_t *udp = (void*)(ip->data);
uint8_t *data = udp->data;
uint16_t i;
for(i = 0; i < len; ++i) {
putchar(data[i]);
}
draw_clr();
data[len - 1] = 0;
draw_str(1, 0, (char*)data);
const char* response = "!!! OK !!!\n";
strcpy((char*)data, response);
udp_reply(frame, strlen(response));
}
void lan_poll(void)
{
uint16_t len;
eth_frame_t *frame = (void*)net_buf;
while((len = enc28j60_read(net_buf, sizeof(net_buf)))) {
eth_filter(frame, len);
}
}
int main(void)
{
bsp_init();
uart0_init();
lan_init();
draw_init();
printf("Start polling...\n");
while(1)
lan_poll();
return 0;
}
IPv6 | IPv4 | исходники
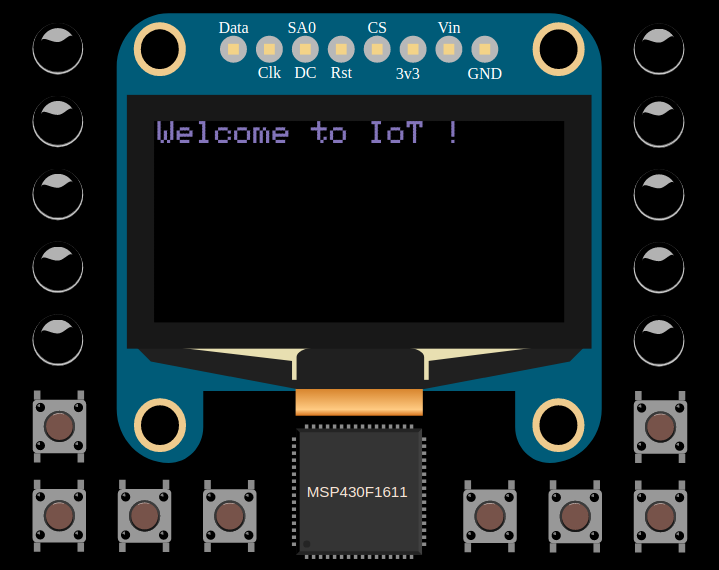
Чтобы вывести данные в дисплей, отправляем девайсу UDP-пакет на любой порт, netcat — удобная утилитка, которая поможет отправлять и принимать данные по сети:
~$ cat <(echo IoT) - | nc -6 -u fe80::0:ff:fe00:42%mazko 12345
В реальном мире на одном адресе может быть много UDP портов, где каждый сервис отвечает за свою логику. Количество портов ограничено с учётом 16-битной адресации т.е. 65536. Все порты разделены на три диапазона — общеизвестные (или системные, 0..1023), зарегистрированные (или пользовательские, 1024..49151) и динамические (или частные, 49152..65535). Например ранее упомянутый NTP протокол использует порт 123 (UDP), DNS порт 53 и т.д.
Далее TCP.
There are comments.