Как уже упоминалось ранее, между строкой запроса, которую вводит пользователь для осуществления поиска и методом, реализующим непосредственно сам поиск в Lucene, имеется промежуточный класс - Query. Этот класс можно создавать программно - причём можно создавать даже очень сложный Query, используя комбинацию из нескольких из них, тем самым достигая наилучших результатов поиска. Однако последнее не всегда целесообразно делать вручную - в Lucene уже имеется определённый синтаксис запросов, который позволяет распарсить вводимую пользователем строку и тем самым автоматически создать сложный Query. До этого момента мы не использовали данный механизм, принудительно экранируя все запросы методом QueryParser.escape:
server/src/main/java/server/QueryHelper.java
package server;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.Query;
import common.LuceneBinding;
final class QueryHelper {
static Query generate(final String story) throws ParseException {
final QueryParser parser = new MultiFieldQueryParser(
new String[] {
LuceneBinding.TITLE_FIELD,
LuceneBinding.CONTENT_FIELD,
/* Russian */
LuceneBinding.RUS_TITLE_FIELD,
LuceneBinding.RUS_CONTENT_FIELD,
/* English */
LuceneBinding.ENG_TITLE_FIELD,
LuceneBinding.ENG_CONTENT_FIELD },
LuceneBinding.getAnalyzer());
/* Operator OR is used by default */
parser.setDefaultOperator(QueryParser.Operator.AND);
/* Here are some changes for SYNTAX DEMO */
parser.setAllowLeadingWildcard(true);
return parser.parse(story);
}
}
Теперь можно откинуться на спинку кресла и насладиться результатами:
~$ mvn clean install -pl server/ jetty:run
Правда в нашем случае итоговую картину сильно смазывают языковые анализаторы - RussianAnalyzer и EnglishAnalyzer, поэтому предлагаю не полениться и вернуться на время освоения текущего материала к использованию в процессе поиска только одного анализатора - StandardAnalyzer. Так будет лучше видно, в чем именно соль того или иного запроса:
server/src/main/java/server/QueryHelper.java
package server;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.Query;
import common.LuceneBinding;
final class QueryHelper {
static Query generate(String story) throws ParseException {
QueryParser parser = new MultiFieldQueryParser(
new String[] { LuceneBinding.TITLE_FIELD, LuceneBinding.CONTENT_FIELD },
LuceneBinding.getAnalyzer());
/* Operator OR is used by default */
parser.setDefaultOperator(QueryParser.Operator.AND);
/* Here are some changes for SYNTAX DEMO */
parser.setAllowLeadingWildcard(true);
return parser.parse(story);
}
}
server/src/main/java/server/HighlightedSearchItem.java
package server;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.search.highlight.SimpleSpanFragmenter;
import common.LuceneBinding;
public class HighlightedSearchItem extends DefaultSearchItem {
public final String highlightedTitle, highlightedContent;
HighlightedSearchItem(final String title, final String content, final String uri,
final float score, final String highlightedTitle, final String highlightedContent) {
super(title, content, uri, score);
this.highlightedContent = highlightedContent;
this.highlightedTitle = highlightedTitle;
}
}
class HighlightedAgregator extends Aggregator<HighlightedSearchItem> {
private Highlighter highlighter;
private final String tryHighlight(final String text, final String[] fields)
throws IOException, InvalidTokenOffsetsException {
if (text == null) {
return null;
}
if (this.highlighter == null) {
final QueryScorer scorer = new QueryScorer(this.query);
this.highlighter = new Highlighter(
new SimpleHTMLFormatter("[mazko.github.io]", "[/mazko.github.io]"),
scorer);
this.highlighter.setTextFragmenter(new SimpleSpanFragmenter(scorer, 330));
}
for (final String field : fields) {
final String highlighted = this.highlighter.getBestFragment(
LuceneBinding.getAnalyzer(), field, text);
if (highlighted != null) {
return highlighted;
}
}
return text;
}
@Override
HighlightedSearchItem aggregate(final ScoreDoc sd)
throws IOException, CorruptIndexException, InvalidTokenOffsetsException {
final Document doc = this.indexSearcher.doc(sd.doc);
final String title = doc.get(LuceneBinding.TITLE_FIELD);
final String content = doc.get(LuceneBinding.CONTENT_FIELD);
final String highlightedTitle = this.tryHighlight(
title, new String[] { LuceneBinding.TITLE_FIELD });
final String highlightedContent = this.tryHighlight(
content, new String[] { LuceneBinding.CONTENT_FIELD });
return new HighlightedSearchItem(title, content,
doc.get(LuceneBinding.URI_FIELD),
sd.score, highlightedTitle, highlightedContent);
}
}
Синтаксис
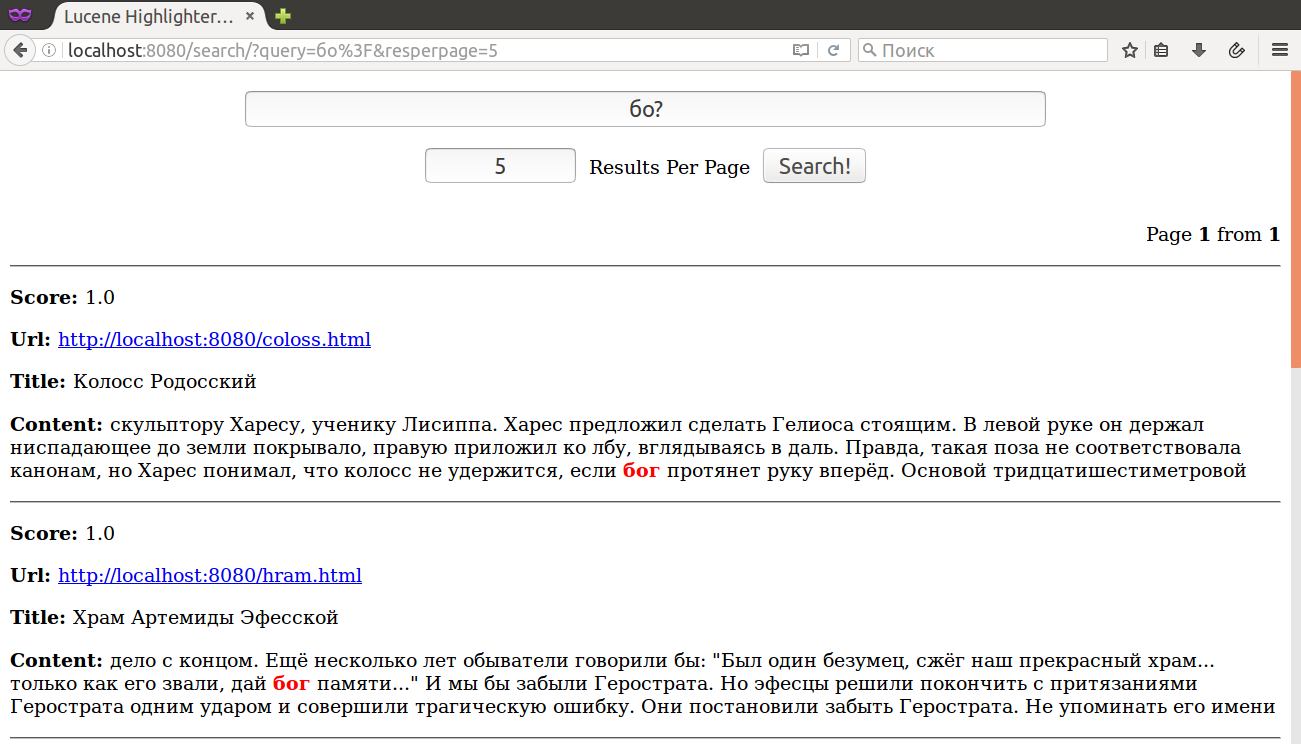
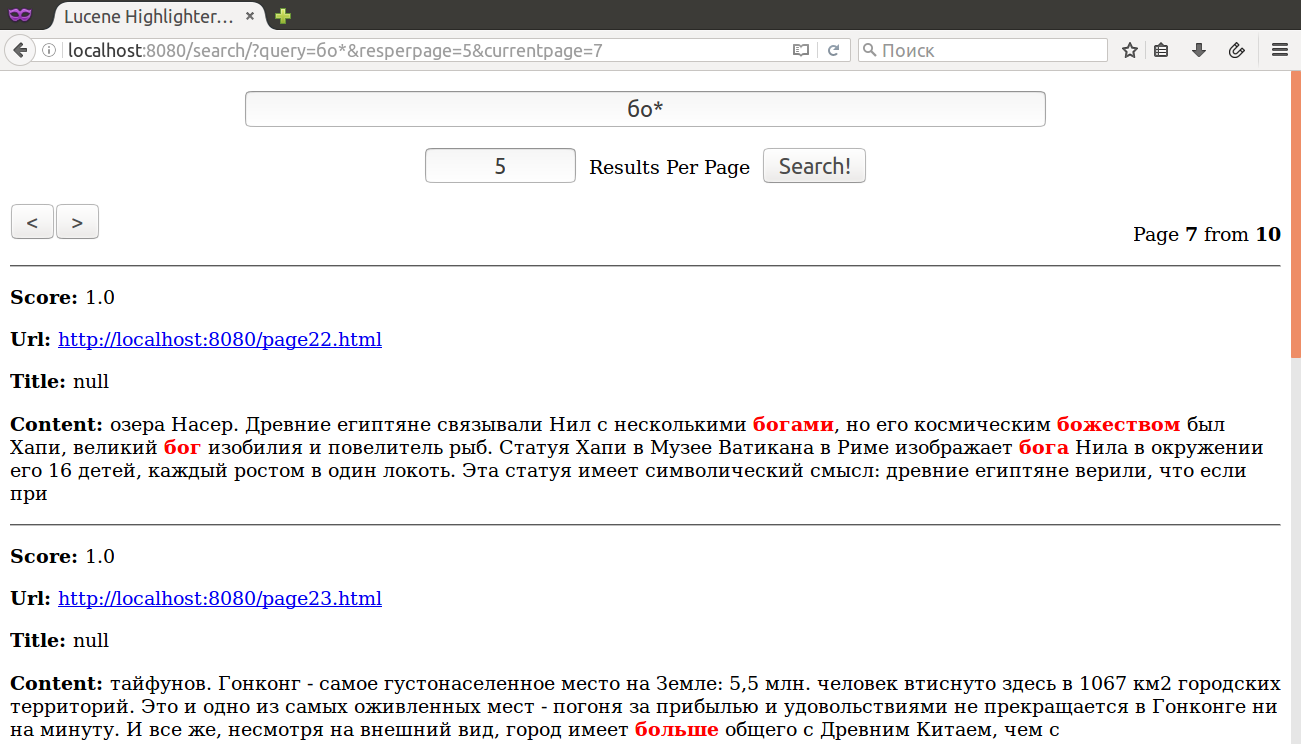
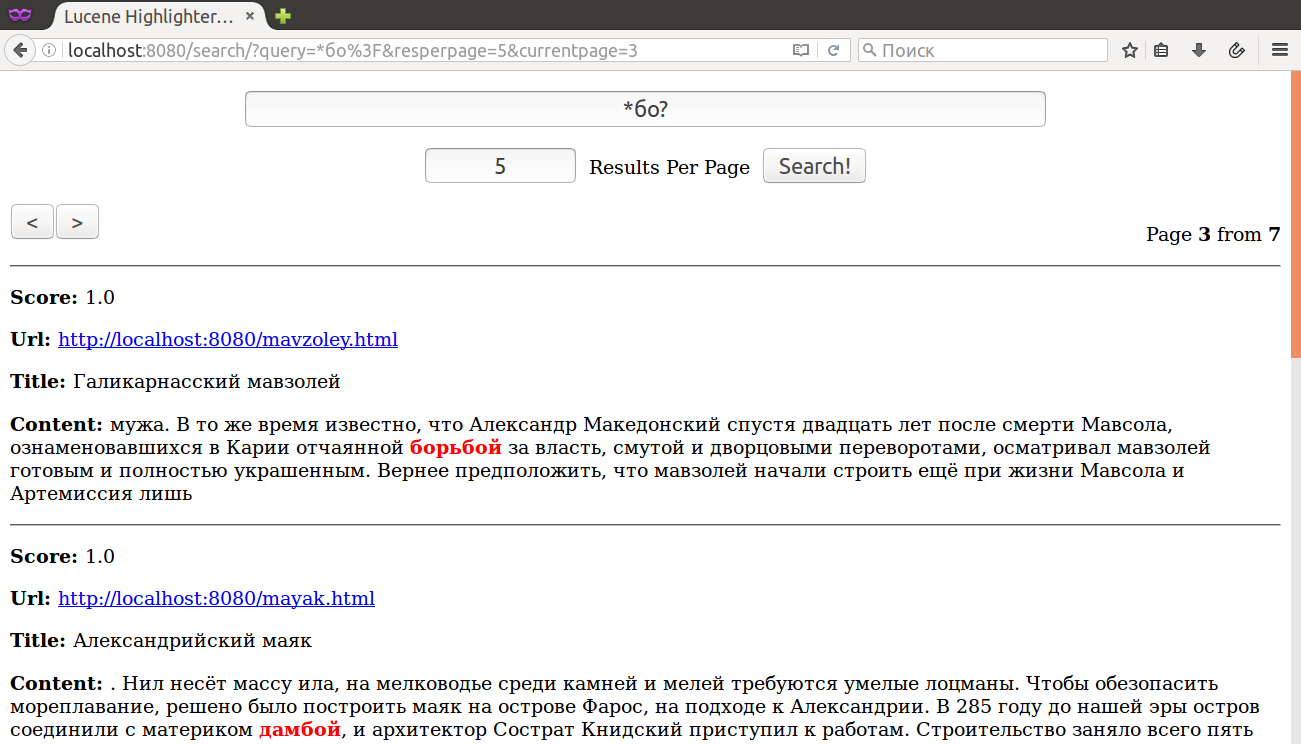
Семейство WildcardQuery: бо? - вместо '?' может быть ОДИН любой символ; бо* любое количество 0..n любых символов после 'бо'
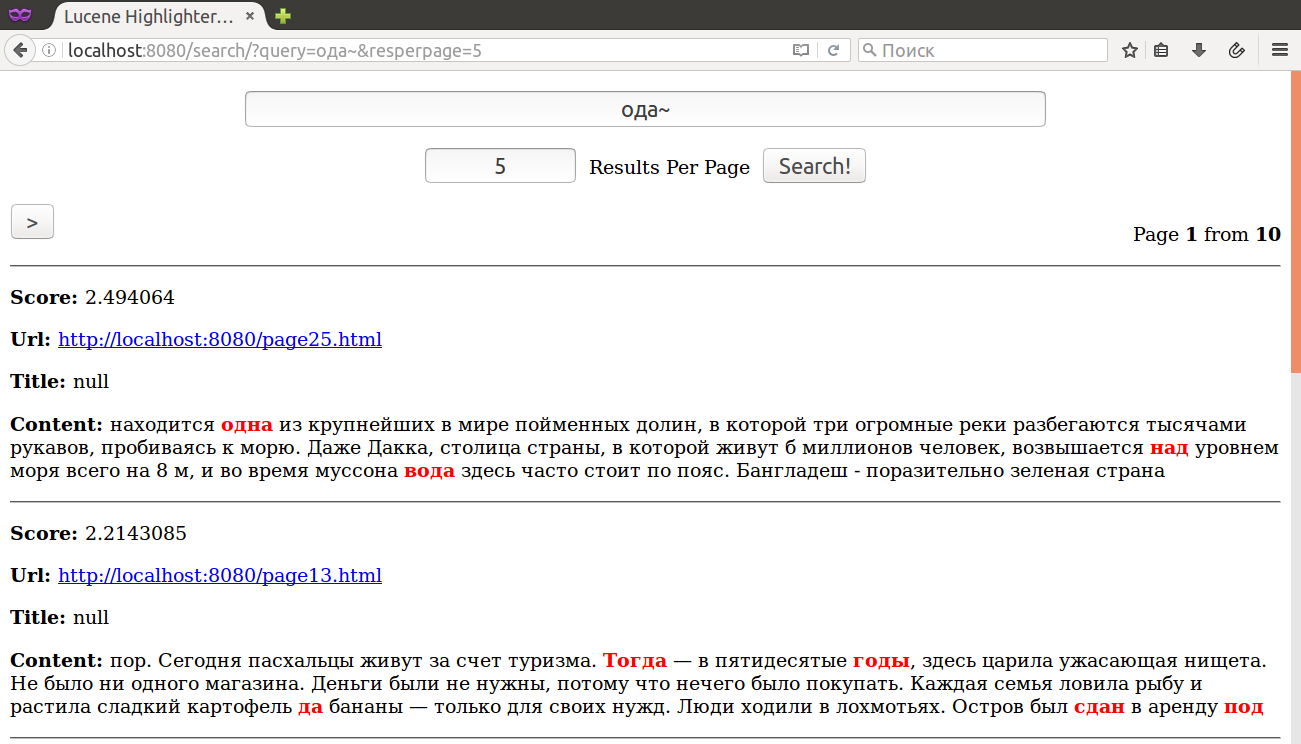
FuzzyQuery - ищутся похожие слова:
Поиск по конкретным полям в индексе:
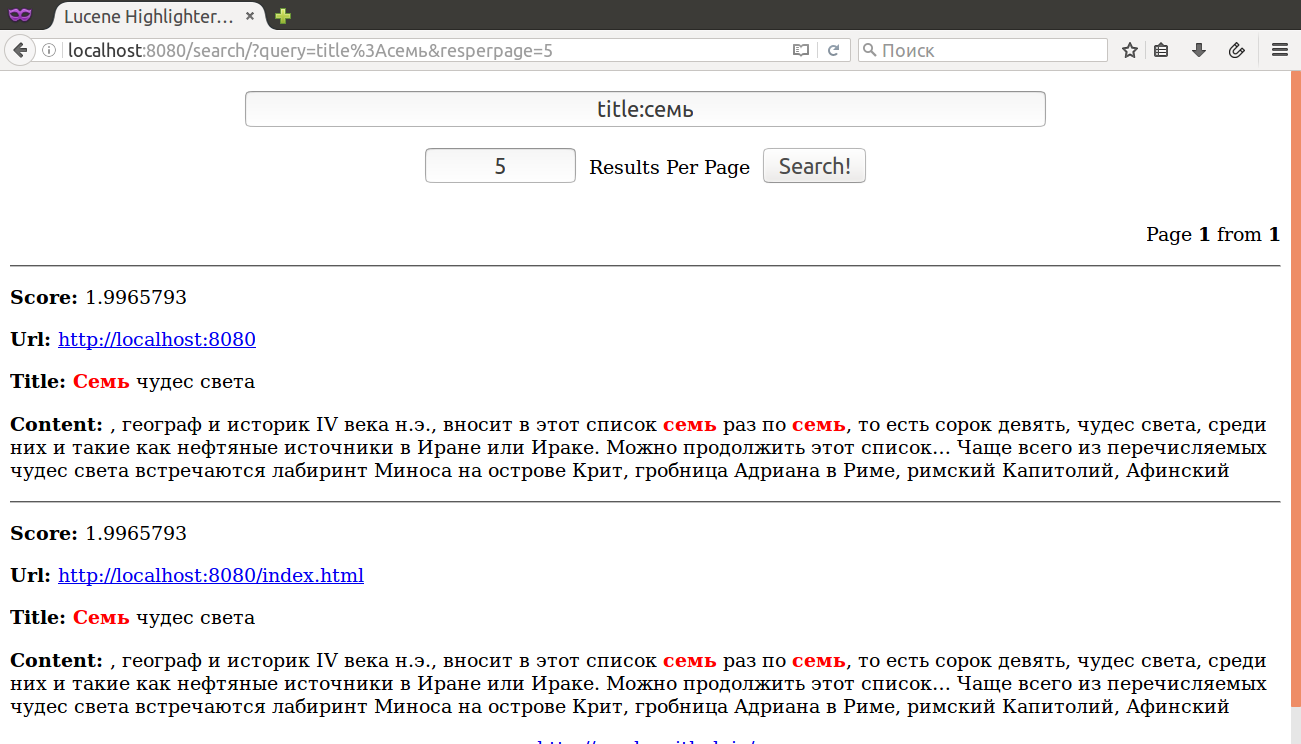
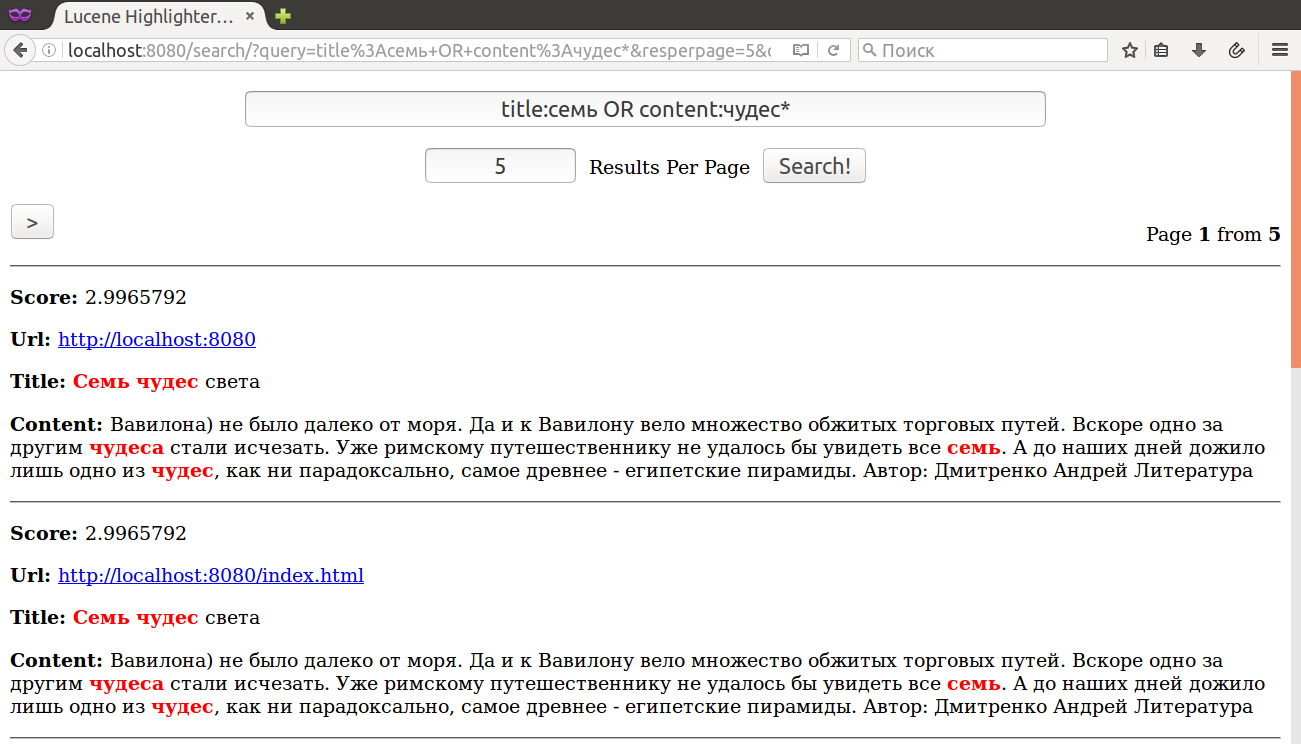
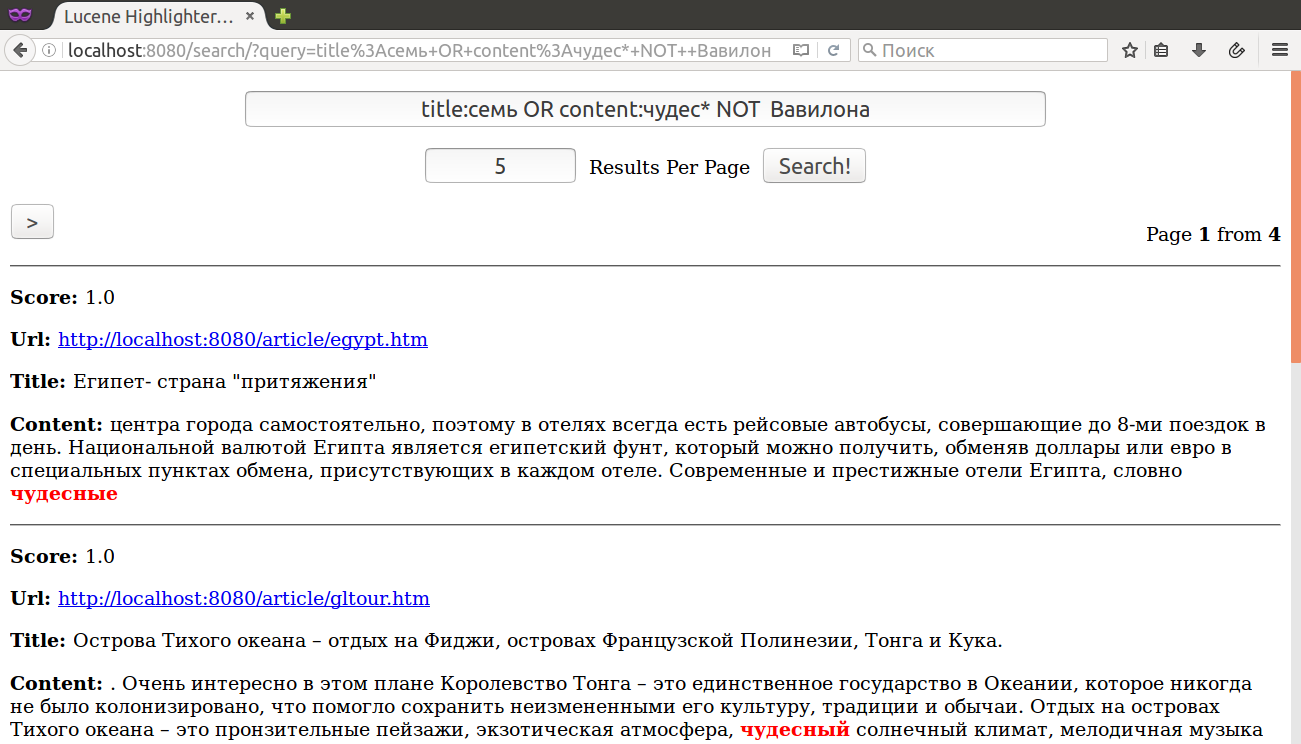
Булевые запросы:
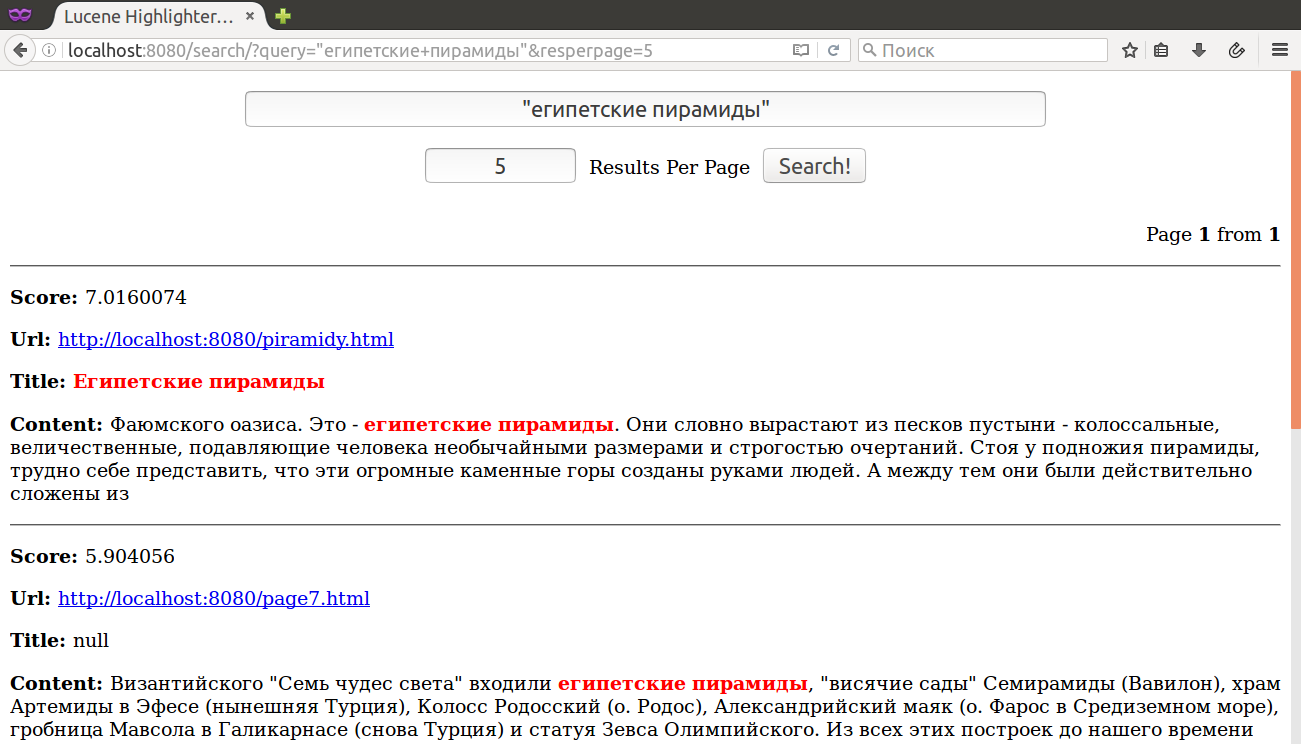
PhraseQuery - поиск фразы. С помощью '~' можно задать максимальное расстояние между словами фразы.
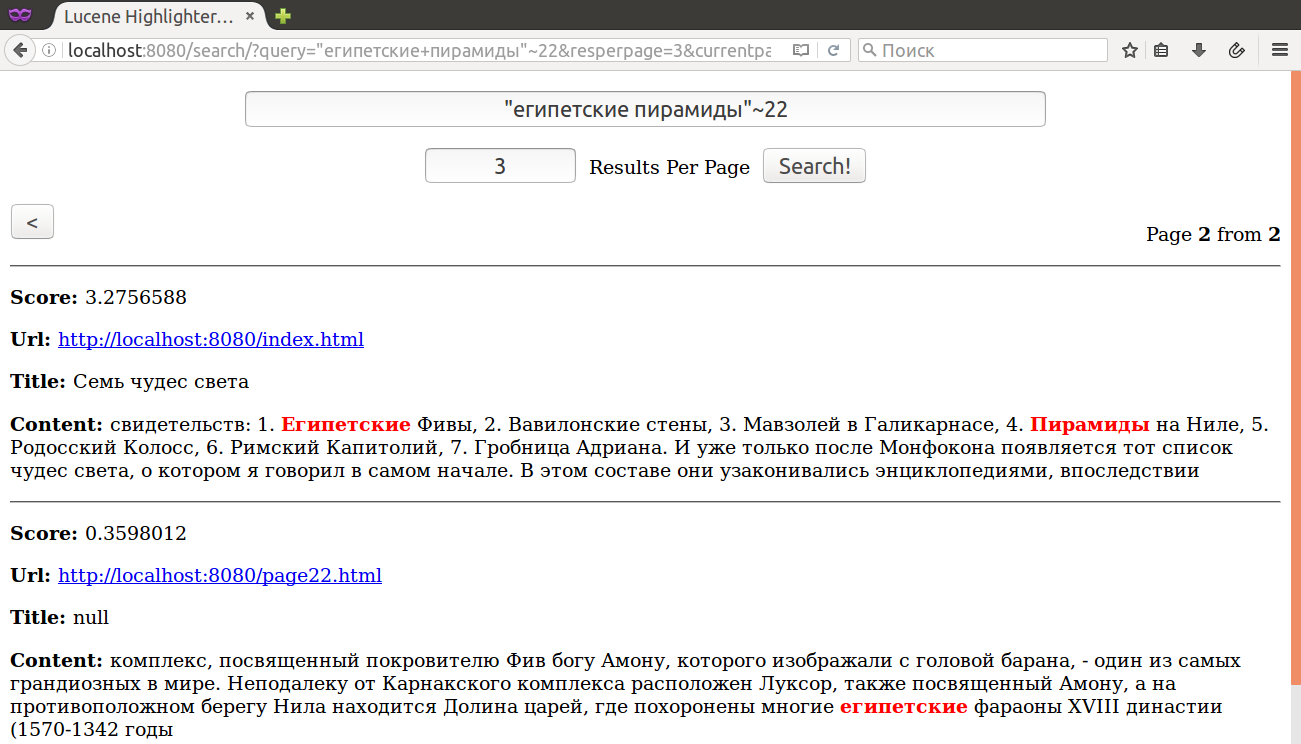
Далее рассмотрим фасетный поиск.