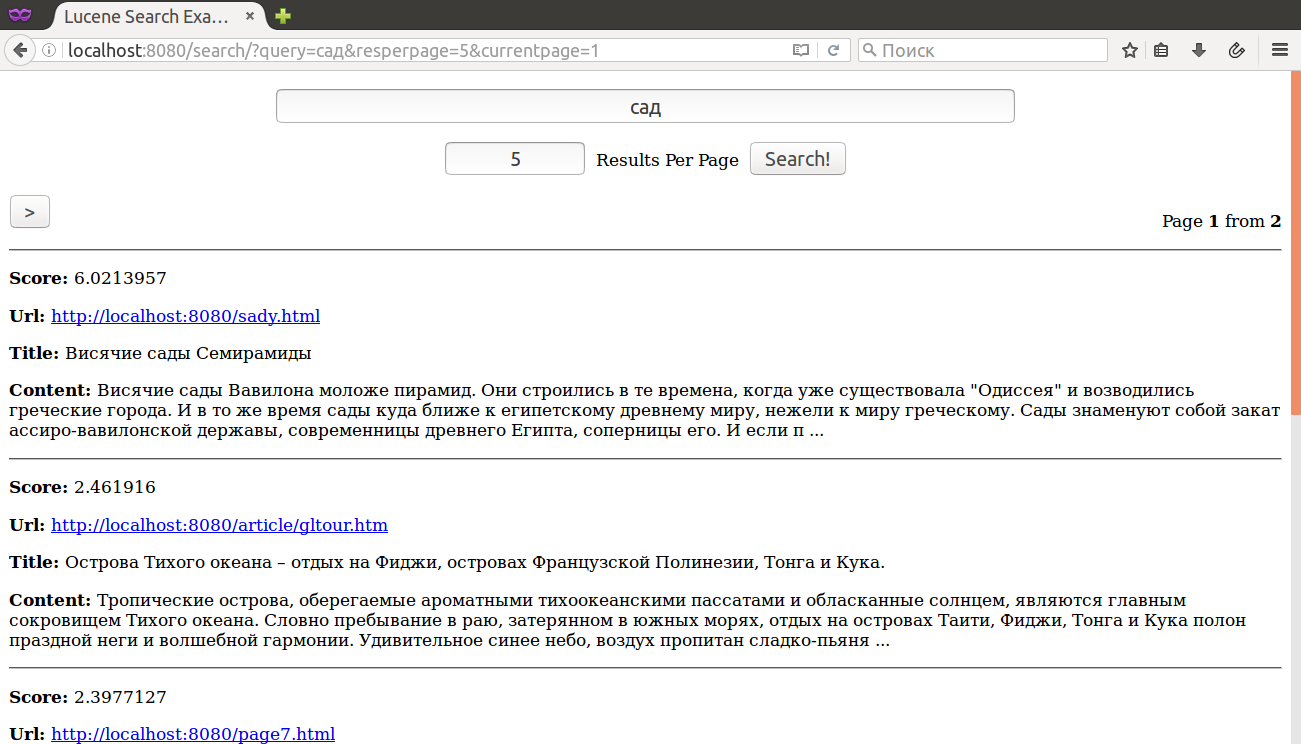
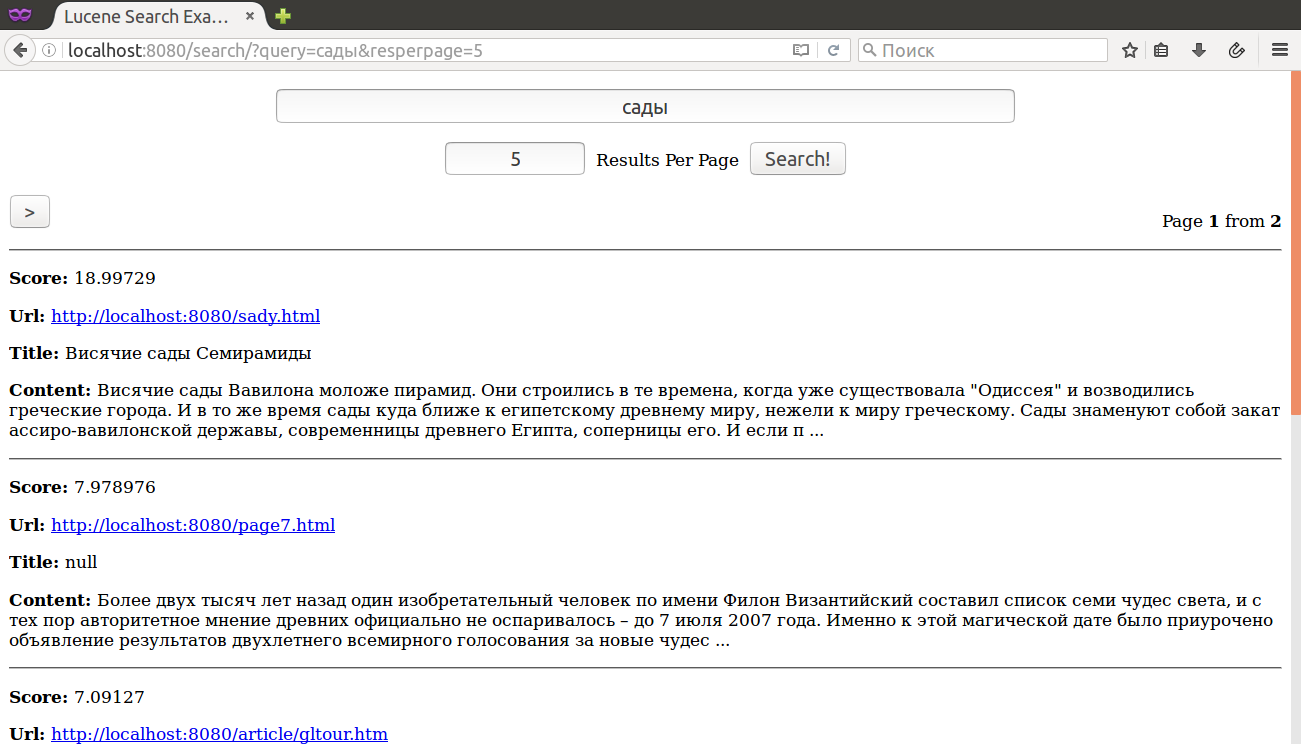
Как Вам поиск ? Мы вводим в качестве запроса слово сад и получаем 0 (НОЛЬ) результатов, в то время как это же слово в другом падеже - сады - даёт целых 6 (ШЕСТЬ) ! Всё дело в том, что в процессе индексации / поиска использовался стандартный анализатор текста - StandardAnalyzer, который ничего не знает об особенностях того или иного языка. Какие вообще существуют алгоритмы для программного выделения основы слова ? Очень распространёнными, и, что немаловажно в контексте процесса индексации - быстрыми, являются алгоритмы стемминга, среди которых, наиболее популярными и часто используемыми являются Стеммеры Портера - впервые опубликованные ещё в далёком 1980 году. Введите ОДНО слово, выберите язык и нажмите кнопку "Стеммер!":
Хорошая новость - в Lucene уже есть готовые анализаторы для многих распространённых языков, в том числе и для русского, которые можно взять из коробки. Вопрос тут несколько в иной плоскости - как организовать поиск, задействовав одновременно несколько из них - для русскоязычных сайтов было бы неплохо предусмотреть и Английский (EnglishAnalyzer) и Русский (RussianAnalyzer). Можно попробовать автоматически определять язык текста и задействовать соответствующий анализатор, однако у такого решения есть подводный камень. Всё дело в том, что точность определения языка очень сильно зависит от объёма текста - чем он меньше, тем больше вероятность ошибки и это особенно актуально для процесса поиска, когда пользователь вводит всего несколько слов в строку запроса. Очевидно, что алгоритм с использованием автоматического определения языка необходимо дорабатывать.
В данном примере будет представлено альтернативное решение, реализованное исключительно средствами Lucene. В структуре индекса добавятся дополнительные соответствующие конкретному языку поля. Для каждого поля в Lucene можно задать свой анализатор, используя класс PerFieldAnalyzerWrapper:
common/src/main/java/common/LuceneBinding.java
package common;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.HashMap;
import java.util.Map;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.en.EnglishAnalyzer;
import org.apache.lucene.analysis.miscellaneous.PerFieldAnalyzerWrapper;
import org.apache.lucene.analysis.ru.RussianAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
/* This class is used both by Crawler and SearchServlet */
public final class LuceneBinding {
public static final Path INDEX_PATH = Paths.get(
System.getProperty("user.home"), "lucene-tutorial-index");
public static final String URI_FIELD = "uri";
public static final String TITLE_FIELD = "title";
public static final String CONTENT_FIELD = "content";
/* Russian */
public static final String RUS_TITLE_FIELD = "rustitle";
public static final String RUS_CONTENT_FIELD = "ruscontent";
/* English */
public static final String ENG_TITLE_FIELD = "engtitle";
public static final String ENG_CONTENT_FIELD = "engcontent";
public static Analyzer getAnalyzer() {
final Map<String, Analyzer> analyzers = new HashMap<String, Analyzer>();
analyzers.put(LuceneBinding.RUS_TITLE_FIELD, new RussianAnalyzer());
analyzers.put(LuceneBinding.RUS_CONTENT_FIELD, new RussianAnalyzer());
analyzers.put(LuceneBinding.ENG_TITLE_FIELD, new EnglishAnalyzer());
analyzers.put(LuceneBinding.ENG_CONTENT_FIELD, new EnglishAnalyzer());
return new PerFieldAnalyzerWrapper(new StandardAnalyzer(), analyzers);
}
}
Данные поля необходимо добавить в индекс - можно с параметром setStored(false), поскольку в нашем случае у документа Document уже имеются соответствующие поля, хранящие оригинальные значения (созданные с параметром setStored(true)) - зачем дублировать информацию и тем самым раздувать размеры индекса.
crawler/src/main/java/crawler/LuceneIndexer.java
package crawler;
import java.io.Closeable;
import java.io.IOException;
import org.apache.log4j.Logger;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import common.LuceneBinding;
class LuceneIndexer implements Closeable {
private static final Logger logger = Logger.getLogger(LuceneIndexer.class.getName());
/* IndexWriter is completely thread safe */
private IndexWriter indexWriter = null;
@Override
public void close() throws IOException {
if (this.indexWriter != null) {
LuceneIndexer.logger.info("Closing Index < " +
LuceneBinding.INDEX_PATH + " > NumDocs: " + this.indexWriter.numDocs());
this.indexWriter.close();
this.indexWriter = null;
LuceneIndexer.logger.info("Index Closed OK!");
} else {
throw new IOException("Index already closed");
}
}
public void new_index() throws IOException {
final Directory directory = FSDirectory.open(LuceneBinding.INDEX_PATH);
final IndexWriterConfig iwConfig = new IndexWriterConfig(LuceneBinding.getAnalyzer());
iwConfig.setOpenMode(OpenMode.CREATE);
this.indexWriter = new IndexWriter(directory, iwConfig);
}
public void add(final String url, final String html) {
final String title = HtmlHelper.extractTitle(html);
final String content = HtmlHelper.extractContent(html);
LuceneIndexer.logger.info("***** " + url + " *****");
if (title != null) {
LuceneIndexer.logger.info(title);
}
LuceneIndexer.logger.info(content);
final Document doc = new Document();
final FieldType urlType = new FieldType();
urlType.setIndexOptions(IndexOptions.DOCS);
urlType.setStored(true);
urlType.setTokenized(false);
urlType.setStoreTermVectorOffsets(false);
urlType.setStoreTermVectorPayloads(false);
urlType.setStoreTermVectorPositions(false);
urlType.setStoreTermVectors(false);
doc.add(new Field(LuceneBinding.URI_FIELD, url, urlType));
final FieldType tokType = new FieldType();
tokType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);
tokType.setStored(true);
tokType.setTokenized(true);
tokType.setStoreTermVectorOffsets(true);
tokType.setStoreTermVectorPayloads(true);
tokType.setStoreTermVectorPositions(true);
tokType.setStoreTermVectors(true);
if (title != null) {
doc.add(new Field(LuceneBinding.TITLE_FIELD, title, tokType));
}
doc.add(new Field(LuceneBinding.CONTENT_FIELD, content, tokType));
// Language setStored(false) - we already have original value
final FieldType lngType = new FieldType();
lngType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);
lngType.setStored(false);
lngType.setTokenized(true);
lngType.setStoreTermVectorOffsets(true);
lngType.setStoreTermVectorPayloads(true);
lngType.setStoreTermVectorPositions(true);
lngType.setStoreTermVectors(true);
/* Russian */
if (title != null) {
doc.add(new Field(LuceneBinding.RUS_TITLE_FIELD, title, lngType));
}
doc.add(new Field(LuceneBinding.RUS_CONTENT_FIELD, content, lngType));
/* English */
if (title != null) {
doc.add(new Field(LuceneBinding.ENG_TITLE_FIELD, title, lngType));
}
doc.add(new Field(LuceneBinding.ENG_CONTENT_FIELD, content, lngType));
try {
if (this.indexWriter != null) {
this.indexWriter.addDocument(doc);
}
} catch (final IOException ex) {
LuceneIndexer.logger.error(ex);
}
}
}
Для поиска по нескольким полям одновременно используем уже известный MultiFieldQueryParser, просто расширив перечень интересующих нас полей:
server/src/main/java/server/QueryHelper.java
package server;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.queryparser.classic.QueryParserBase;
import org.apache.lucene.search.Query;
import common.LuceneBinding;
final class QueryHelper {
static Query generate(final String story) throws ParseException {
final QueryParser parser = new MultiFieldQueryParser(
new String[] {
LuceneBinding.TITLE_FIELD,
LuceneBinding.CONTENT_FIELD,
/* Russian */
LuceneBinding.RUS_TITLE_FIELD,
LuceneBinding.RUS_CONTENT_FIELD,
/* English */
LuceneBinding.ENG_TITLE_FIELD,
LuceneBinding.ENG_CONTENT_FIELD },
LuceneBinding.getAnalyzer());
/* Operator OR is used by default */
parser.setDefaultOperator(QueryParser.Operator.AND);
return parser.parse(QueryParserBase.escape(story));
}
}
После переидексации сайта результаты поисковой выдачи выглядят уже намного лучше:
~$ mvn clean install && bash -c 'mvn -pl server/ jetty:run & sleep 10 && \
mvn -pl crawler/ exec:java -Dexec.mainClass="crawler.App" & \
trap "kill -TERM -$$" SIGINT ; wait'
Далее реализуем подсветку найденных вхождений.