С индексом в Lucene, кажется, разобрались - на очереди поиск. Давайте немножко подумаем. Предположим, поиском будет заниматься класс LuceneSearcher, а результатом поиска должен быть класс TakeResult, в котором будет достаточно информации для реализации постраничной выдачи. Что может измениться в будущем ? На данном этапе мы можем предположить, что единицей поиска будет класс в котором будут два поля - content и title. А если изменится сайт или нам понадобиться какая-то дополнительная информация в результатах выдачи ? Процесс создания и наполнения класса - единицы поиска лучше вынести за пределы LuceneSearcher, для этой цели можно задействовать механизм шаблонов (generic):
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>tutorial.lucene</groupId>
<artifactId>parent</artifactId>
<packaging>pom</packaging>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>6.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>6.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>6.0.0</version>
</dependency>
</dependencies>
<modules>
<module>server</module>
<module>crawler</module>
<module>common</module>
</modules>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
server/src/main/java/server/TakeResult.java
package server;
import java.io.IOException;
import java.util.Collection;
import java.util.Collections;
import org.apache.lucene.queryparser.classic.ParseException;
public final class TakeResult<T> {
public final int totalHits;
private final Collection<T> items;
protected TakeResult(final int totalHits, final Collection<T> items) {
this.totalHits = totalHits;
this.items = items;
}
public Collection<T> getItems() {
if (this.items != null) {
return Collections.unmodifiableCollection(this.items);
}
return null;
}
interface ITakeble<T> {
TakeResult<T> Take(int count, int start)
throws ParseException, IOException, InstantiationException, IllegalAccessException;
}
}
server/src/main/java/server/LuceneSearcher.java
package server;
import java.io.IOException;
import java.nio.file.Path;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.TopScoreDocCollector;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
abstract class Aggregator<T> {
protected Query query;
protected IndexSearcher indexSearcher;
abstract T aggregate(ScoreDoc sd) throws IOException, CorruptIndexException;
}
class LuceneSearcher<T, A extends Aggregator<T>> implements TakeResult.ITakeble<T> {
private final String story;
private final Class<A> classA;
/* IndexReader is thread safe - one instance for all requests */
private static volatile IndexReader indexReader;
LuceneSearcher(final Class<A> classA,
final Path indexPath, final String story) throws IOException {
this.story = story;
this.classA = classA;
if (LuceneSearcher.indexReader == null) {
synchronized (LuceneSearcher.class) {
if (LuceneSearcher.indexReader == null) {
final Directory dir = FSDirectory.open(indexPath);
LuceneSearcher.indexReader = DirectoryReader.open(dir);
}
}
}
}
@Override
public TakeResult<T> Take(final int count, final int start)
throws ParseException, IOException, InstantiationException, IllegalAccessException {
final int nDocs = start + count;
final Query query = QueryHelper.generate(this.story);
final IndexSearcher indexSearcher = new IndexSearcher(LuceneSearcher.indexReader);
final TopScoreDocCollector collector = TopScoreDocCollector.create(Math.max(nDocs, 1));
indexSearcher.search(query, collector);
final TopDocs topDocs = collector.topDocs();
if (nDocs <= 0) {
return new TakeResult<T>(topDocs.totalHits, null);
}
final ScoreDoc[] scoreDocs = topDocs.scoreDocs;
final int length = scoreDocs.length - start;
if (length <= 0) {
return new TakeResult<T>(topDocs.totalHits, null);
}
final List<T> items = new ArrayList<T>(length);
final A aggregator = this.classA.newInstance();
aggregator.query = query;
aggregator.indexSearcher = indexSearcher;
for (int i = start; i < scoreDocs.length; i++) {
items.add(i - start, aggregator.aggregate(scoreDocs[i]));
}
return new TakeResult<T>(topDocs.totalHits, items);
}
}
Процесс создания нового экземпляра класса IndexReader, в зависимости от размера текущего индекса, может быть очень затратным с точки зрения ресурсов системы - CPU и ОЗУ. Поэтому в документации настоятельно рекомендуется создать в программе ОДИН экземпляр данного класса и использовать его совместно между всеми потоками приложения по мере необходимости - IndexReader изначально проектировался как потокобезопасный (thread safe). С учётом вышесказанного в нашем случае (см. LuceneSearcher.java) IndexReader может существовать только в одном экземпляре, используется ленивая инициализация по принципу double checked locking (блокировка с двойной проверкой), в связи с чем поле indexReader объявлено как volatile. Если содержимое индекса измениться извне (что вполне возможно в реальных условиях), IndexReader необходимо обновить - для этой цели целесообразней не создавать новый экземпляр, а лучше использовать специальный метод IndexReader.reopen(). В противном случае, если не обновить экземпляр IndexReader, новые данные, добавленные в индекс, в результаты поисковой выдачи не попадут.
Когда пользователь вводит какое-либо слово / фразу в качестве поискового запроса, это просто строка, чтобы с ней мог работать Lucene её необходимо преобразовать / распарсить в экземпляр класса Query . Почему именно так будет понятно, когда будет описан синтаксис запросов для Lucene. В нашем случае используется MultiFieldQueryParser, который позволяет осуществлять поиск одновременно(параллельно) по нескольким заданным полям в индексе:
server/src/main/java/server/QueryHelper.java
package server;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.queryparser.classic.QueryParserBase;
import org.apache.lucene.search.Query;
import common.LuceneBinding;
final class QueryHelper {
static Query generate(final String story) throws ParseException {
final QueryParser parser = new MultiFieldQueryParser(
new String[] {
LuceneBinding.TITLE_FIELD,
LuceneBinding.CONTENT_FIELD },
LuceneBinding.getAnalyzer());
/* Operator OR is used by default */
parser.setDefaultOperator(QueryParser.Operator.AND);
return parser.parse(QueryParserBase.escape(story));
}
}
Теперь можно реализовать простой класс, который содержит информацию о найденном документе. Помимо известных нам title, content и uri появляется новая сущность - score. Это числовой показатель соответствия найденного документа тому запросу, который использовался Lucene для его поиска - релевантность.
server/src/main/java/server/DefaultSearchItem.java
package server;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.search.ScoreDoc;
import common.LuceneBinding;
public class DefaultSearchItem {
public final String title, content, uri;
public final float score;
DefaultSearchItem(final String title,
final String content, final String uri, final float score) {
this.uri = uri;
this.title = title;
this.content = content;
this.score = score;
}
}
class DefaultAgregator extends Aggregator<DefaultSearchItem> {
@Override
DefaultSearchItem aggregate(final ScoreDoc sd) throws IOException, CorruptIndexException {
final Document doc = this.indexSearcher.doc(sd.doc);
return new DefaultSearchItem(
doc.get(LuceneBinding.TITLE_FIELD),
doc.get(LuceneBinding.CONTENT_FIELD),
doc.get(LuceneBinding.URI_FIELD),
sd.score);
}
}
На данном этапе уже имеются все необходимые механизмы для реализии процесса поиска с постраничной выдачей результатов. В качестве передаваемой jsp-представлению модели данных будет выступать экземпляр класса TakeResult<DefaultSearchItem>:
server/src/main/java/server/SearchServlet.java
package server;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import common.LuceneBinding;
public class SearchServlet extends HttpServlet {
public final static String QUERY_INPUT = "query";
public final static String RESULTS_PER_PAGE = "resperpage";
public final static String CURRENT_PAGE = "currentpage";
@Override
public void doGet(final HttpServletRequest req, final HttpServletResponse res)
throws ServletException, IOException {
final String query = req.getParameter(SearchServlet.QUERY_INPUT);
final String itemsPerPage = req.getParameter(SearchServlet.RESULTS_PER_PAGE);
final String currentPage = req.getParameter(SearchServlet.CURRENT_PAGE);
if (query != null && !query.isEmpty()) {
int currentPageInt = 1, itemsPerPageInt = 10;
try {
currentPageInt = Integer.parseInt(currentPage);
} catch (final NumberFormatException e) {
}
try {
itemsPerPageInt = Integer.parseInt(itemsPerPage);
} catch (final NumberFormatException e) {
}
try {
req.setAttribute("searchmodel",
new LuceneSearcher<DefaultSearchItem, DefaultAgregator>(
DefaultAgregator.class,
LuceneBinding.INDEX_PATH, query.trim())
.Take(
itemsPerPageInt,
(currentPageInt - 1) * itemsPerPageInt));
} catch (final Exception e) {
throw new ServletException(e);
}
}
this.getServletContext().getRequestDispatcher("/index.jsp").forward(req, res);
}
}
server/src/main/webapp/index.jsp
<jsp:directive.page language="java"
contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8" />
<jsp:directive.page import="server.TakeResult" />
<jsp:directive.page import="server.SearchServlet" />
<jsp:directive.page import="server.DefaultSearchItem" />
<%!
public String escapeHTML(String s) {
if (s == null) return null;
s = s.replaceAll("&", "&");
s = s.replaceAll("<", "<");
s = s.replaceAll(">", ">");
s = s.replaceAll("\"", """);
s = s.replaceAll("'", "'");
return s;
}
public String ellipsize(String s, int max) {
if (s.length() > max) {
final String end = " ...";
s = s.substring(0, max - end.length()).trim() + end;
}
return s;
}
%>
<%
final TakeResult<DefaultSearchItem> model =
(TakeResult<DefaultSearchItem>)request
.getAttribute("searchmodel");
final String qDefValue = escapeHTML(request
.getParameter(SearchServlet.QUERY_INPUT));
final int rPerPage = request.getParameter(
SearchServlet.RESULTS_PER_PAGE) == null ? 5 :
Integer.parseInt(request
.getParameter(SearchServlet.RESULTS_PER_PAGE));
final int cPage = request.getParameter(
SearchServlet.CURRENT_PAGE) == null ? 1 :
Integer.parseInt(request
.getParameter(SearchServlet.CURRENT_PAGE));
%>
<html>
<head>
<title>Lucene Search Example</title>
<meta http-equiv="Content-Type"
content="text/html; charset=UTF-8" />
</head>
<body>
<form name="search" action="/search" accept-charset="UTF-8">
<p align="center">
<input name="<%= SearchServlet.QUERY_INPUT %>"
<% if(qDefValue != null) { %>
value="<%= qDefValue %>"
<% } %>
size="55" style="text-align:center;"/>
</p>
<p align="center">
<input name="<%= SearchServlet.RESULTS_PER_PAGE %>"
size="5" value="<%= rPerPage %>"
style="text-align:center;" />
Results Per Page
<input type="submit" value="Search!"/>
</p>
</form>
<% if(model != null && model.getItems() != null) { %>
<p style="float:right;">
Page <b><%= cPage %></b> from <b>
<%= (int)Math.ceil(
((float)model.totalHits) / rPerPage)
%></b>
</p>
<% } %>
<% if(model != null && model.getItems() != null) { %>
<% if(cPage > 1) { %>
<form name="search" action="/search"
accept-charset="UTF-8"
style="float:left;">
<% if(qDefValue != null) { %>
<input type="hidden"
name="<%= SearchServlet.QUERY_INPUT %>"
value="<%= qDefValue %>" />
<% } %>
<input type="hidden"
name="<%= SearchServlet.RESULTS_PER_PAGE %>"
value="<%= rPerPage %>" />
<input type="hidden"
name= "<%= SearchServlet.CURRENT_PAGE %>"
value="<%= cPage - 1 %>"/>
<input type="submit"
value="<%= escapeHTML("<") %>"/>
</form>
<% } %>
<% if(model.totalHits > cPage * rPerPage) { %>
<form name="search" action="/search"
accept-charset="UTF-8" >
<% if(qDefValue != null) { %>
<input type="hidden"
name="<%= SearchServlet.QUERY_INPUT %>"
value="<%= qDefValue %>" />
<% } %>
<input type="hidden"
name="<%= SearchServlet.RESULTS_PER_PAGE %>"
value="<%= rPerPage %>" />
<input type="hidden"
name= "<%= SearchServlet.CURRENT_PAGE %>"
value="<%= cPage + 1 %>"/>
<input type="submit"
value="<%= escapeHTML(">") %>"/>
</form>
<% } %>
<% } %>
<p align="center" style="clear:both;">
<% if(model != null) { %>
<% if(model.getItems() != null) { %>
<p>
<% for(DefaultSearchItem item :
model.getItems()) { %>
<hr/>
<p><b>Score: </b><%= item.score %></p>
<p><b>Url: </b>
<a href="<%= item.uri %>">
<%= item.uri %>
</a>
</p>
<p><b>Title: </b>
<%= escapeHTML(item.title) %>
</p>
<p><b>Content: </b>
<%= escapeHTML(
ellipsize(item.content, 330))
%>
</p>
<% } %>
</p>
<% } else { %>
I'm sorry I couldn't find what you were looking for.
<% } %>
<% } %>
</p>
<p align="center">
<a href="http://mazko.github.io/">http://mazko.github.io/</a>
</p>
</body>
</html>
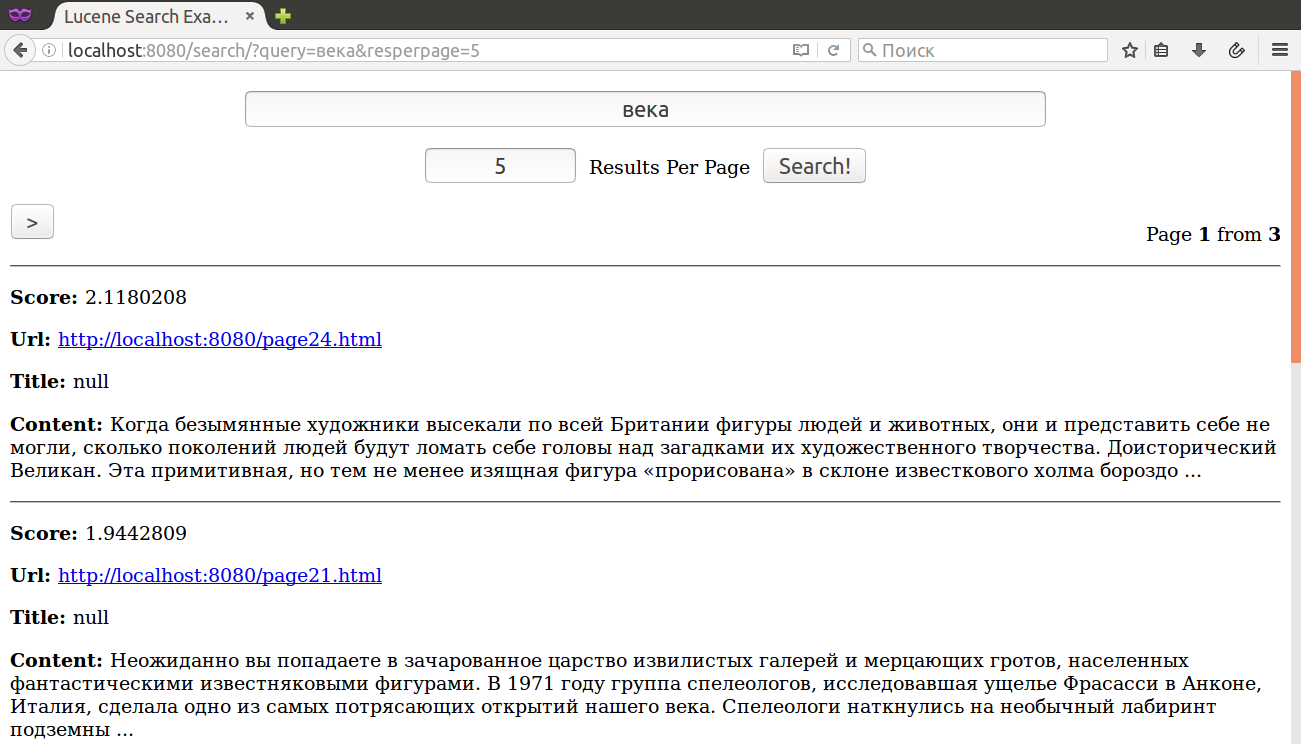
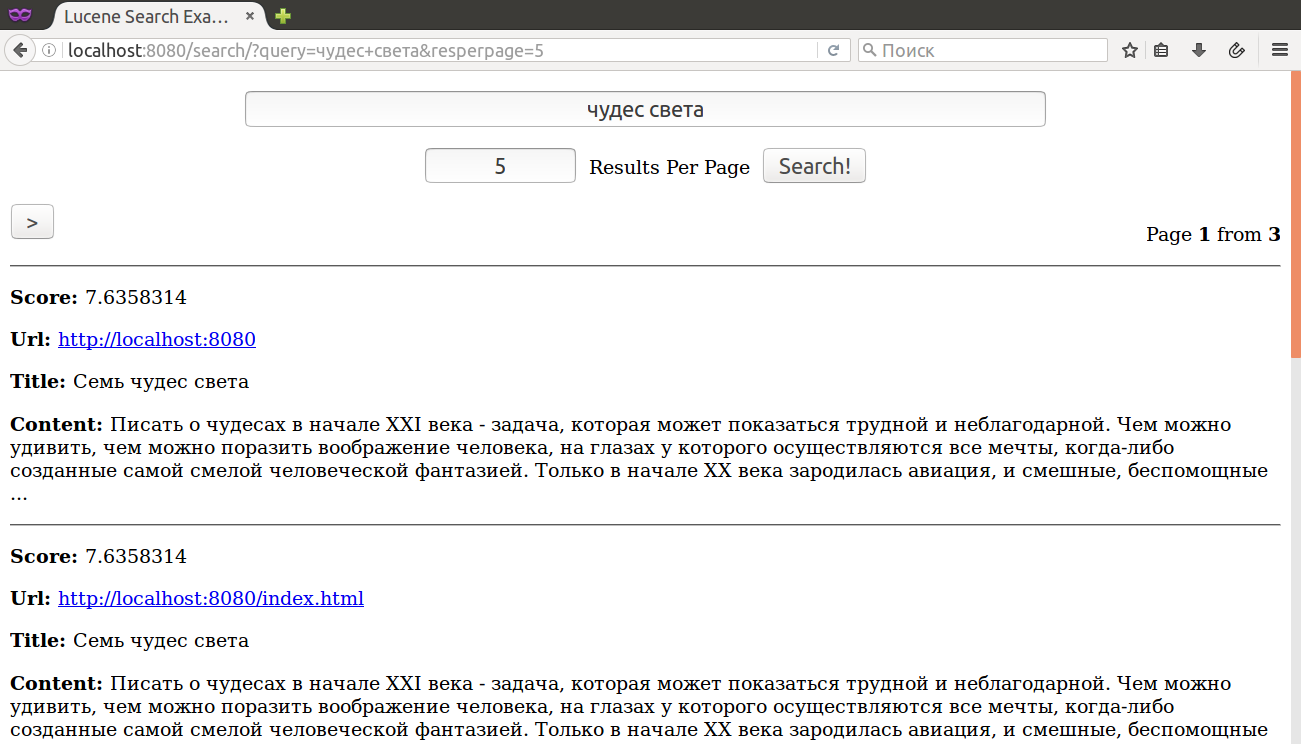
Результат выполнения должен быть таким:
~$ mvn clean install -pl server/ jetty:run
Далее рассмотрим языковые возможности Lucene, особенно интересно посмотреть на русский анализатор - RussianAnalyzer.